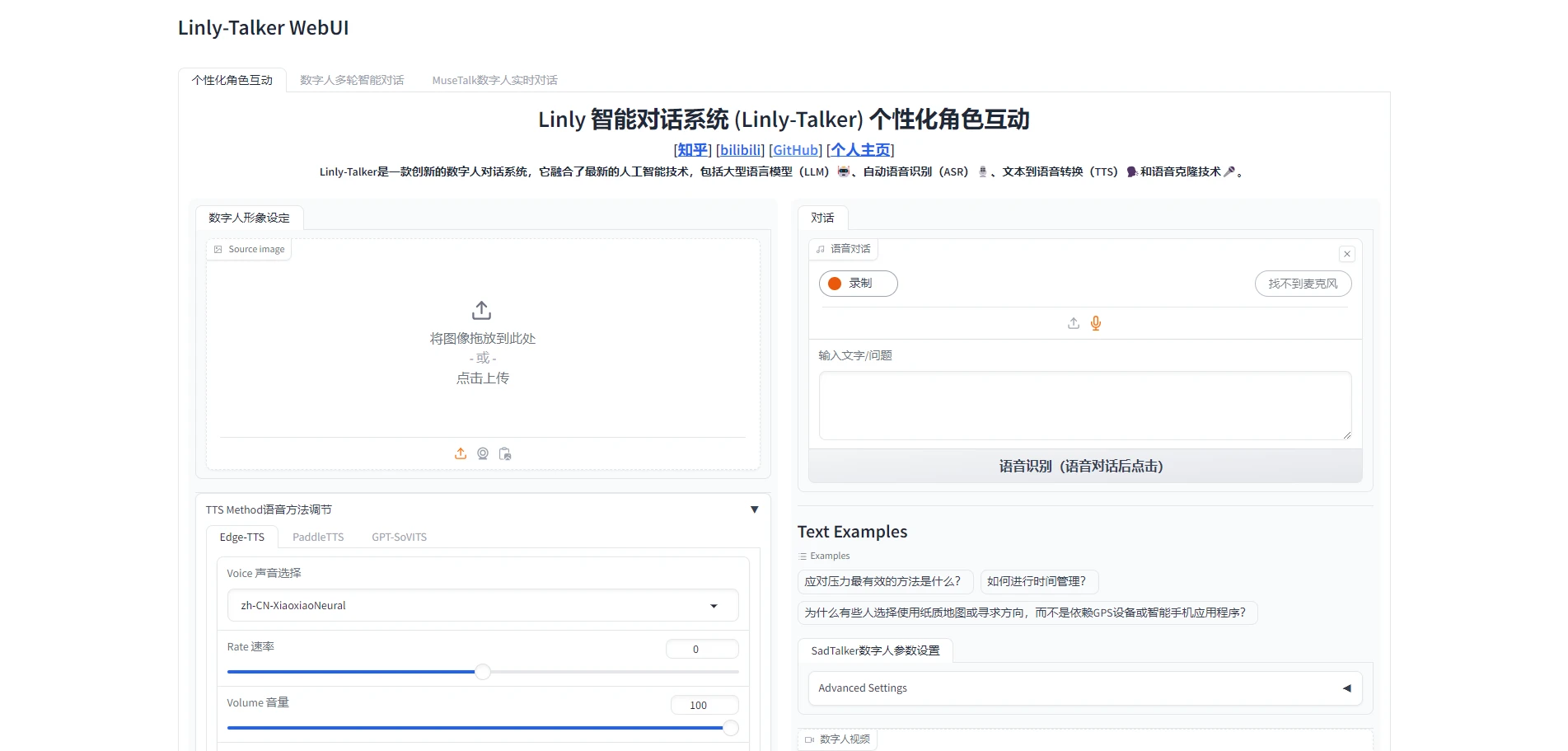
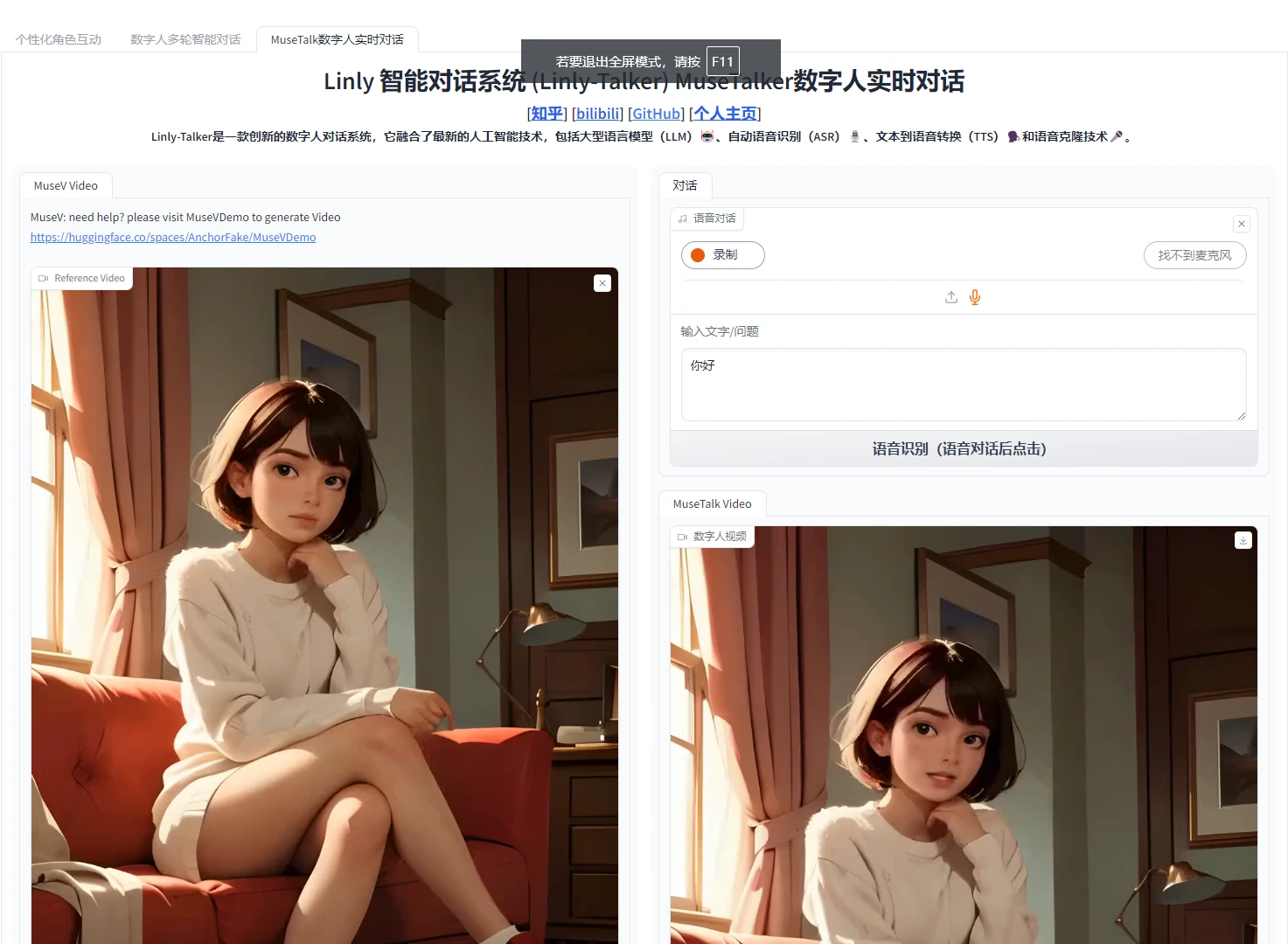
VASA VASA-1是一个由微软亚洲研究院开发的生成框架,能够将静态照片转化为动态的口型同步视频。该框架利用精确的唇音同步、丰富的面部表情和自然的头部运动,创造出高度逼真的虚拟人物形象。VASA-1支持在线生成高分辨率视频,具有低延迟的特点,并且能够处理多种类型的输入,如艺术照片、歌唱音频和非英语语音。此外,通过灵活的生成控制,用户可以调整输出的多样性和适应性。 AI项目与工具 2025年06月12日 83 点赞 0 评论 723 浏览
AniTalker AniTalker是一款先进的AI工具,能将单张静态人像与音频同步转化为生动的动画对话视频。它通过自监督学习捕捉面部动态,采用通用运动表示和身份解耦技术减少对标记数据的依赖,同时结合扩散模型和方差适配器生成多样且可控的面部动画。AniTalker支持视频驱动和语音驱动两种方式,并具备实时控制动画生成的能力。 AI项目与工具 2025年06月12日 62 点赞 0 评论 856 浏览
Moshi Moshi是一款由法国Kyutai实验室开发的端到端实时音频多模态AI模型,具备听、说、看的能力,并能模拟70种不同的情绪和风格进行交流。Moshi具有多模态交互、情绪和风格表达、实时响应低延迟、语音理解与生成、文本和音频混合预训练以及本地设备运行等特点。它支持英语和法语,主要应用于虚拟助手、客户服务、语言学习、内容创作、辅助残障人士、研究和开发、娱乐和游戏等领域。 AI项目与工具 2025年06月12日 73 点赞 0 评论 855 浏览
EchoMimic EchoMimic是一款由阿里蚂蚁集团开发的AI数字人开源项目,通过深度学习模型结合音频和面部标志点,创造出高度逼真的动态肖像视频。该工具支持音频同步动画、面部特征融合、多模态学习和跨语言能力,适用于娱乐、教育和虚拟现实等领域。其独特的技术原理包括音频特征提取、面部标志点定位、面部动画生成和多模态学习,使用了卷积神经网络(CNN)、循环神经网络(RNN)和生成对抗网络(GAN)等深度学习模型,实现 AI项目与工具 2025年06月12日 79 点赞 0 评论 940 浏览
飞船 Kraft 飞船 Kraft 是一款由快手开发的AI智能对话应用,支持自然语言对话、个性化虚拟角色创建、内容创作辅助等功能。用户可通过飞船 Kraft 进行信息查询、日常生活助手、学习辅助及内容创作等活动。该应用还支持高度定制化和语音交互功能。 AI项目与工具 2025年06月12日 84 点赞 0 评论 555 浏览