TurboScribe TurboScribe是一款利用AI技术实现高效音频和视频转录的服务平台,支持98种以上语言的文本转换,具备强大的文件处理能力和多格式兼容性。通过加密技术保障数据安全,提供多样化的成绩单导出选项,并支持说话人识别功能,广泛应用于播客制作、会议记录、学术研究等领域。 AI项目与工具 2025年06月12日 46 点赞 0 评论 631 浏览
Jellypod Jellypod 是一款基于 AI 的播客制作工具,支持从网页、PDF 等多种格式自动生成脚本并转为音频,涵盖 30 多种语言和口音。用户可自定义 AI 主持人,编辑脚本并一键发布到主流平台,具备高质量音频生成与内容管理功能,适用于企业、教育和个人品牌建设等场景。 AI项目与工具 2025年06月12日 80 点赞 0 评论 634 浏览
MMAudio MMAudio是一款基于多模态联合训练的音频合成工具,通过深度学习技术实现视频到音频、文本到音频的精准转换。它具备强大的同步模块,确保生成的音频与视频帧或文本描述时间轴完全对应,适用于影视制作、游戏开发、虚拟现实等多种场景,极大提升了跨模态数据处理的能力和应用效率。 AI项目与工具 2025年06月12日 68 点赞 0 评论 634 浏览
通义万相AI视频 通义万相AI视频是一款基于人工智能的视频生成工具,支持文生视频和图生视频两种模式。用户可输入文字描述或上传图片生成高质量视频,支持多语言、多种艺术风格及音频生成功能,优化中式元素表现,广泛应用于影视、广告、动画设计等多个领域。 AI项目与工具 2025年06月12日 82 点赞 0 评论 634 浏览
Altered AI Altered Studio Voice Editor允许用户通过将他们的声音更改为任何精心策划的组合声音或自定义声音来创建专业的声音表演。它还允许用户创建引人入胜的多角色表演和克隆他们的声音。... 创作工具 2026年06月24日 0 点赞 0 评论 635 浏览
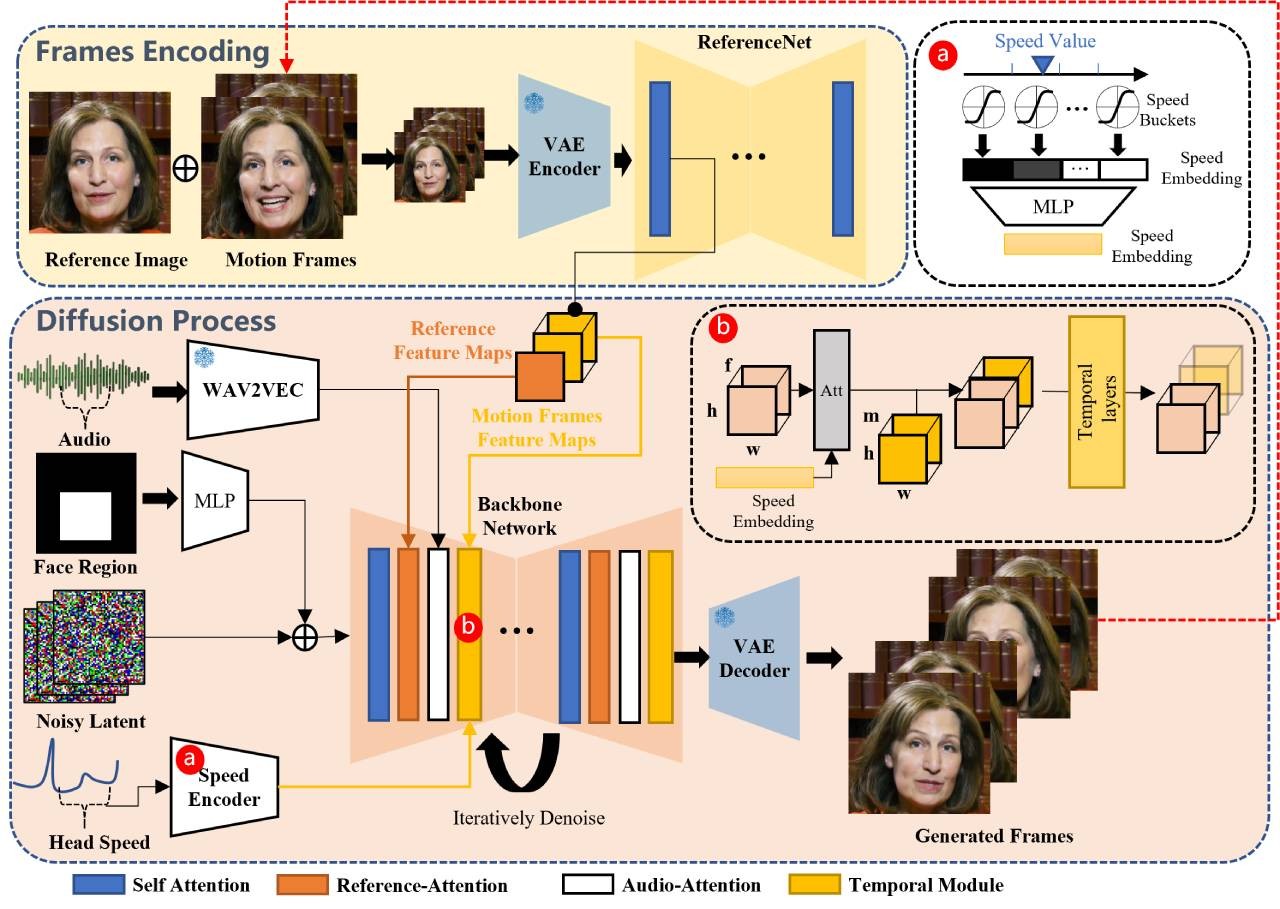
EchoMimicV2 EchoMimicV2是一款由阿里巴巴蚂蚁集团研发的AI数字人动画生成工具,能够基于参考图片、音频剪辑及手部姿势序列生成高质量的半身动画视频。它支持多语言(中英双语)输入,并通过音频-姿势动态协调、头部局部注意力及特定阶段去噪损失等技术手段显著提高了动画的真实度与细节表现力,适用于虚拟主播、在线教育、娱乐游戏等多个领域。 AI项目与工具 2025年06月12日 17 点赞 0 评论 635 浏览
CoGenAV CoGenAV是一种先进的多模态学习模型,专注于音频和视觉信号的对齐与融合。通过对比特征对齐和生成文本预测的双重目标进行训练,利用同步音频、视频和文本数据,学习捕捉时间对应关系和语义信息。CoGenAV具备音频视觉语音识别、视觉语音识别、噪声环境下的语音处理、语音重建与增强、主动说话人检测等功能,适用于智能助手、视频内容分析、工业应用和医疗健康等多个场景。 AI项目与工具 2025年06月11日 80 点赞 0 评论 636 浏览
Speechelo Speechelo是一款基于先进AI技术的文本转语音工具,支持超过30种性别和语言的声音选择,用户可通过调整语调、速度和音高来自定义语音效果。它兼容主流视频编辑软件,适用于产品演示、教育培训、营销推广等多种场景,助力高效生成高质量语音内容。 AI项目与工具 2025年06月12日 52 点赞 0 评论 638 浏览
Huxe AI Huxe AI是一款基于生成式AI技术的个人音频伴侣应用,旨在为用户提供高度个性化的音频体验。其主要功能包括个性化音频简报、实时问答、减少屏幕时间以及与现有应用的无缝集成。通过连接用户的日历、邮件等数据流,Huxe AI能够生成定制化的语音内容,帮助用户高效管理日程、获取信息并提升学习效率。 AI项目与工具 2025年06月12日 76 点赞 0 评论 639 浏览
Emote Portrait Alive 阿里巴巴发布的EMO,一种音频驱动的AI肖像视频生成框架。通过输入单一的参考图像和语音音频,Emote Portrait Alive可以生成动态的、表情丰富的肖像视频。 Ai开源项目 2025年06月05日 18 点赞 0 评论 641 浏览