光语大模型 无限光年公司发布的一款结合大语言模型与符号推理的AI大模型,光语大模型目的是解决大模型在行业应用中的幻觉问题,提高了模型的可信度和专业性。 Ai平台模型 2025年06月05日 89 点赞 0 评论 842 浏览
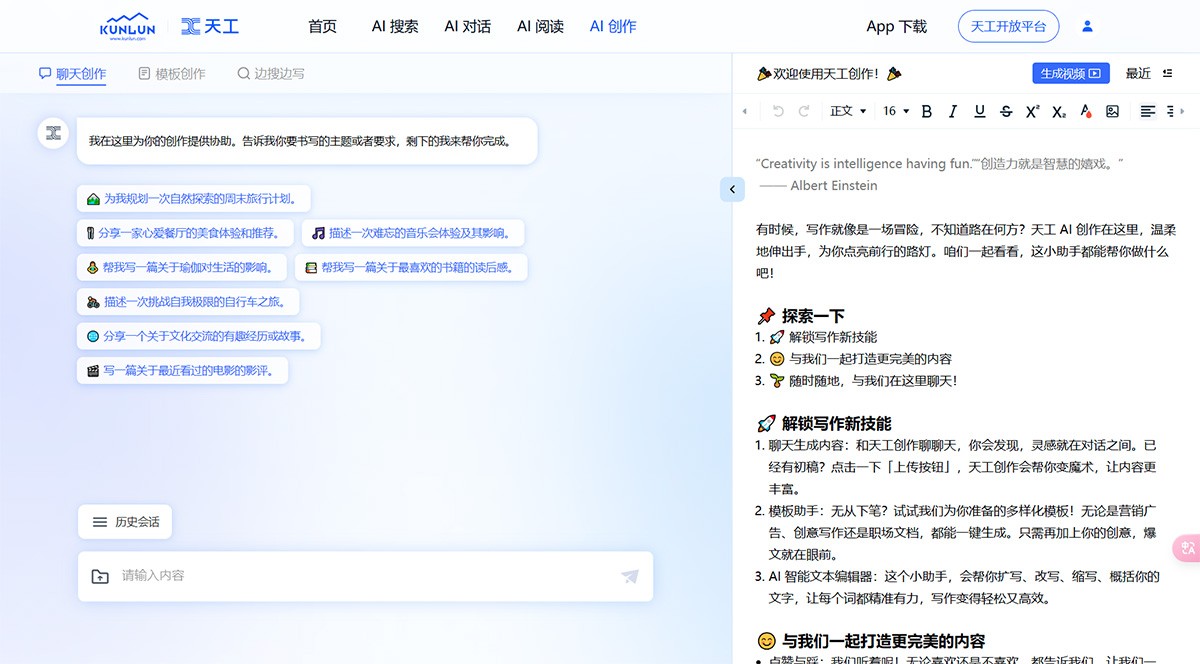
天工大模型 有时候,写作就像是一场冒险,不知道路在何方?天工大模型天工AI创作在这里,温柔地伸出手,为你点亮前行的路灯。咱们一起看看,这小助手都能帮你做什么吧! Ai平台模型 2025年06月05日 99 点赞 0 评论 842 浏览
Llama 3.3 Llama 3.3是一款由Meta AI开发的70B参数大型多语言预训练语言模型,支持英语、德语、法语等8种语言的输入输出。它具备长上下文窗口、高效运行和低成本的特点,可与第三方工具集成,广泛应用于聊天机器人、客户服务、语言翻译、内容创作及教育等领域。 AI项目与工具 2025年06月12日 71 点赞 0 评论 842 浏览
TPO TPO(Test-Time Preference Optimization)是一种在推理阶段优化语言模型输出的框架,通过将奖励模型反馈转化为文本形式,实现对模型输出的动态调整。该方法无需更新模型参数,即可提升模型在多个基准测试中的性能,尤其在指令遵循、偏好对齐、安全性和数学推理等方面效果显著。TPO具备高效、轻量、可扩展的特点,适用于多种实际应用场景。 AI项目与工具 2025年06月12日 83 点赞 0 评论 841 浏览
Aisou.ai Aisou.ai是一款基于大语言模型和检索增强生成技术的智能问答平台,专注于商业信息的高效查询与分析。它支持自然语言提问,提供精准的商业数据分析、实时资讯、竞争对手研究及市场趋势对比等功能,适用于市场分析、投资决策和企业信息查询等多种应用场景。 AI项目与工具 2025年06月12日 47 点赞 0 评论 841 浏览
Lumina Lumina-Image 2.0 是一款开源图像生成模型,基于扩散模型与 Transformer 架构,具有 26 亿参数。它能根据文本描述生成高质量、多风格的图像,支持中英文提示词,并具备强大的复杂提示理解能力。模型支持多种推理求解器,适用于艺术创作、摄影风格图像生成及逻辑推理场景,兼具高效性和灵活性。 AI项目与工具 2025年06月12日 27 点赞 0 评论 841 浏览
HumanOmni HumanOmni 是一款面向人类中心场景的多模态大模型,融合视觉与听觉信息,具备情感识别、面部描述、语音理解等功能。基于大量视频与指令数据训练,采用动态权重调整机制,支持多模态交互与场景理解。适用于影视分析、教育、广告及内容创作等领域,具备良好的可扩展性和灵活性。 AI项目与工具 2025年06月12日 92 点赞 0 评论 841 浏览
Voila Voila是一款开源的端到端语音大模型,支持实时语音交互与多轮对话,具备高保真、低延迟的音频处理能力。集成语音与语言建模功能,支持百万级预设声音及个性化定制,适用于语音助手、角色扮演、语音翻译等场景。采用多尺度Transformer架构,提升语音理解与生成质量,降低开发成本,提高通用性与灵活性。 AI项目与工具 2025年06月11日 60 点赞 0 评论 840 浏览
GTA GTA是一项由上海交通大学与上海AI实验室合作研发的基准测试,专注于评估大型语言模型在真实世界环境中的工具调用能力。它包含229个精心设计的问题,涉及多个领域,并通过多模态输入输出和细粒度评估指标,全面衡量模型的工具使用效率与准确性。GTA可应用于智能助理开发、多模态交互、自动化客户服务、教育及科研等多个领域,助力提升人工智能系统的综合性能。 AI项目与工具 2025年06月12日 20 点赞 0 评论 840 浏览
Ai PDF Ai PDF 是一款强大的工具,可在GPTs平台上运行,旨在有效管理和操作 PDF 文件。它可以处理很大尺寸的PDF文档,Ai PDF的开发重点是提高用户满意度和生产力,无需重复上传文件。 GPTs应用 2025年06月05日 15 点赞 0 评论 840 浏览