AlphaQubit AlphaQubit是一款由谷歌推出的基于人工智能的量子错误解码工具,主要功能包括错误识别与纠正、基于AI的解码、性能优化以及泛化能力提升。它采用量子纠错码(如表面码)、神经网络架构(Transformer)及软读出技术,通过一致性检查与实验数据微调,实现对量子比特状态的高精度预测与校正。AlphaQubit可广泛应用于量子计算机开发、药物发现、材料设计、密码学及优化问题解决等场景。 AI项目与工具 2025年06月12日 82 点赞 0 评论 628 浏览
Vision Parse Vision Parse 是一款开源工具,旨在通过视觉语言模型将 PDF 文件转换为 Markdown 格式。它具备智能识别和提取 PDF 内容的能力,包括文本和表格,并能保持原有格式与结构。此外,Vision Parse 支持多种视觉语言模型,确保解析的高精度与高速度。其应用场景广泛,涵盖学术研究、法律文件处理、技术支持文档以及电子书制作等领域。 AI项目与工具 2025年06月12日 72 点赞 0 评论 628 浏览
Pixel Reasoner Pixel Reasoner是由多所高校联合开发的视觉语言模型,通过像素空间推理增强对视觉信息的理解和分析能力。它支持直接对图像和视频进行操作,如放大区域或选择帧,以捕捉细节。采用两阶段训练方法,结合指令调优和好奇心驱动的强化学习,提升视觉推理性能。在多个基准测试中表现优异,适用于视觉问答、视频理解等任务,广泛应用于科研、教育、工业质检和内容创作等领域。 AI项目与工具 2025年06月11日 30 点赞 0 评论 629 浏览
百度灵医Bot 百度灵医Bot作为百度推出的医疗大模型应用,通过其强大的语言处理能力和专业医疗知识库,为用户提供了全面、安全、智能的医疗健康服务。 创作工具 2026年06月26日 0 点赞 0 评论 629 浏览
汉语新解TextHuman 一个基于李继刚Prompt模板的项目,汉语新解对中文名词进行二次翻译,并生成美观的图像。TextHuman提供智能词汇解释,用户可以输入任何汉语词汇,获得AI生成的新颖解释。 剧本文案 2025年06月05日 30 点赞 0 评论 629 浏览
Vivago AI 北京智象未来科技有限公司面向全球市场推出的一款综合性在线 AI 创作平台,提供视频生成、图片生成、图片agent编辑,数字人生成,3D模型等功能。 Ai绘画生成 2025年06月05日 12 点赞 0 评论 629 浏览
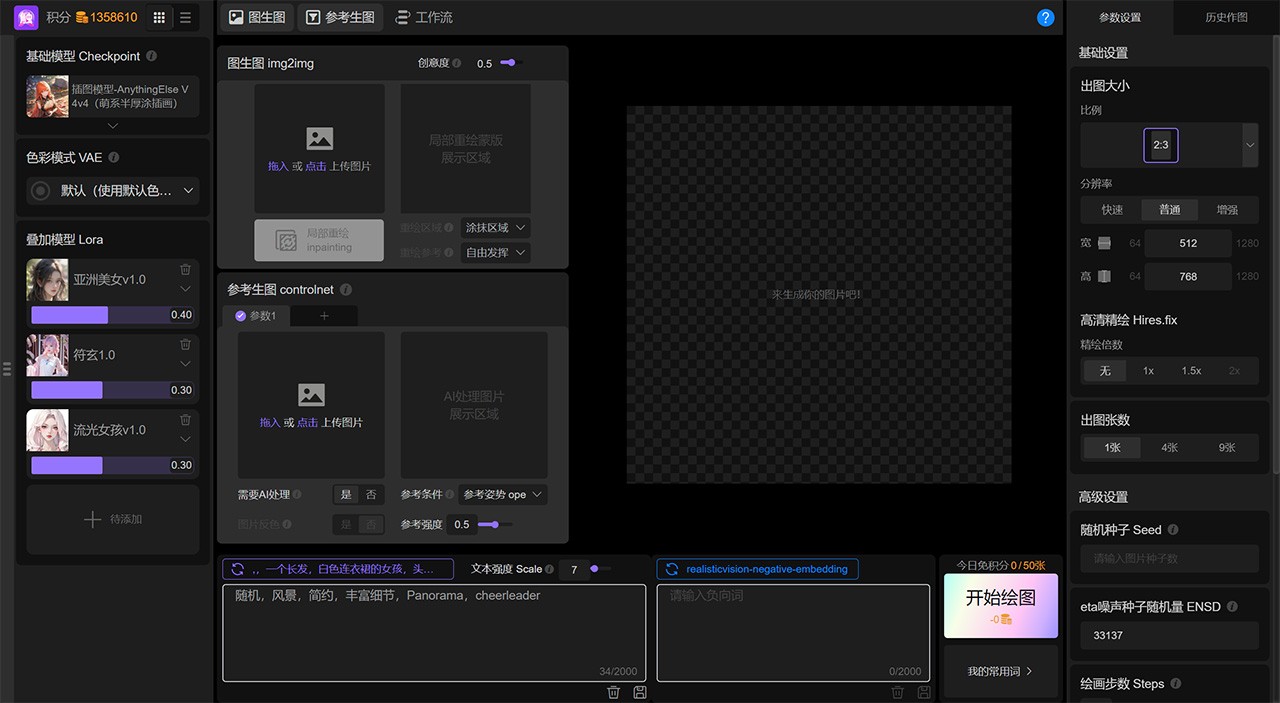
触手AI 触手AI集成了市面上主流绘图软件的完整功能,包括文生图、图生图、ControlNet控图、姿势生图、高清修复、智能修图、模型训练等一系列实用功能。触手AI无需科学上网。 Ai绘画生成 2025年06月05日 44 点赞 0 评论 630 浏览
Vidu 1.5 Vidu 1.5是一款基于多模态视频大模型的AI生成工具,支持参考生视频、图生视频和文生视频生成,通过精准的语义理解能力,在30秒内完成高质量视频创作,适用于影视、动漫、广告等多行业场景,助力创作者高效产出多样化内容。 AI项目与工具 2025年06月12日 80 点赞 0 评论 630 浏览
UltraMem UltraMem是字节跳动推出的超稀疏模型架构,通过优化内存访问和计算效率,显著降低推理成本并提升速度。其核心技术包括多层结构改进、TDQKR和IVE,使模型在保持性能的同时具备更强的扩展性。适用于实时推理、大规模模型部署及多个行业场景。 AI项目与工具 2025年06月12日 11 点赞 0 评论 631 浏览