多模态


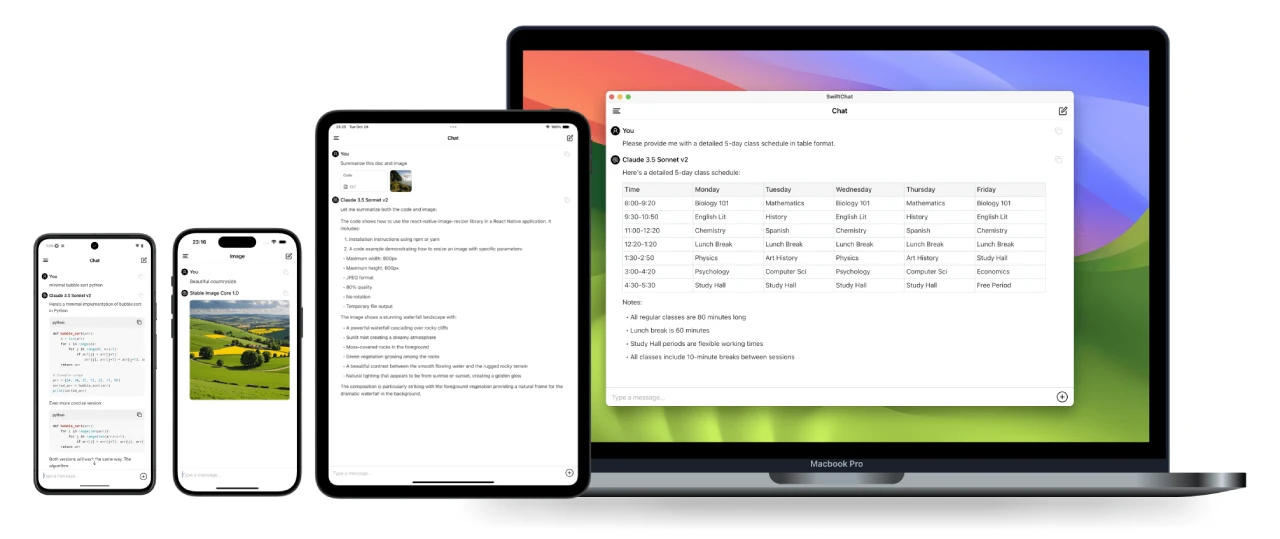
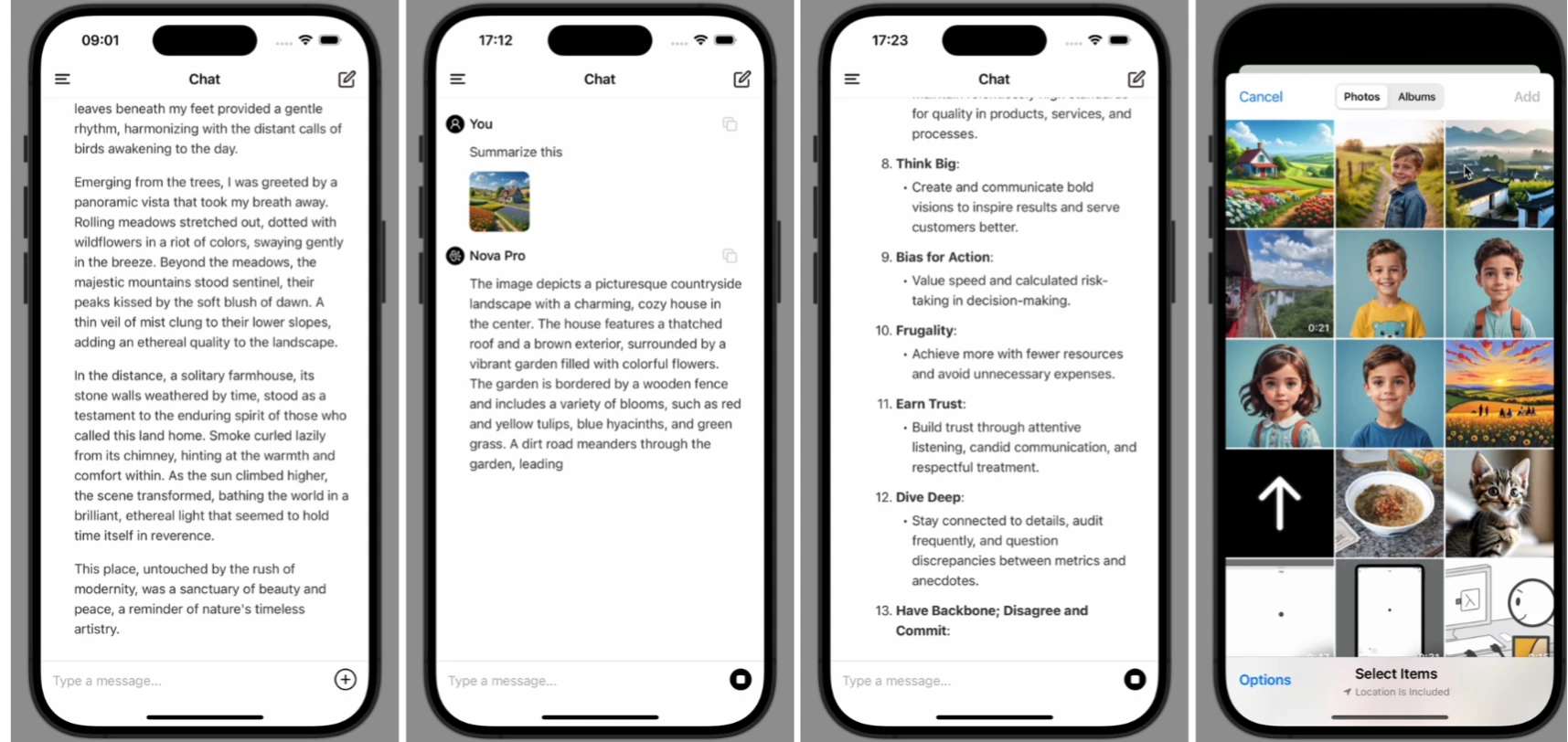

HiDream AI
HiDream AI的目标是帮助用户零基础掌握AIGC的一站式能力,唤醒创造力、赋予作品生命感和价值感,同时解放生产力,提升全流程工作效率。


OpenAI 12天发布会内容全记录,一文快速捕捉亮点信息
OpenAI举办为期12天的系列发布活动,推出包括强化微调技术、Sora视频生成工具、ChatGPT Canvas和高级语音模式在内的多项创新功能,涵盖推理模型、搜索升级和跨平台集成,显著提升AI工具的性能与应用范围。



