FancyVideo FancyVideo是一款由360公司与中山大学合作开发的AI文生视频模型,采用创新的跨帧文本引导模块(CTGM)。它能够根据文本描述生成连贯且动态丰富的视频内容,支持高分辨率视频输出,并保持时间上的连贯性。作为开源项目,FancyVideo提供了详尽的文档和代码库,便于研究者和开发者深入研究和应用。主要功能包括文本到视频生成、跨帧文本引导、时间信息注入及时间亲和度细化等。 AI项目与工具 2025年06月12日 28 点赞 0 评论 643 浏览
Deepfakes Web 一个使用人工智能技术通过交换脸部来轻松生成视频的在线应用程序。该应用程序在云端运行,确保用户数据的隐私。 Ai图片处理 2025年06月05日 23 点赞 0 评论 643 浏览
Video Ocean Video Ocean是一款基于AI技术的视频生成平台,主要功能包括文生视频、图生视频及角色生视频。它允许用户通过文本、图片或自定义角色生成高质量的视频内容,适用于多种应用场景如社交媒体营销、教育培训、影视制作等。此外,Video Ocean还注重提升视频的质量与细节,确保最终效果既美观又实用。 AI项目与工具 2025年06月12日 70 点赞 0 评论 642 浏览
Emote Portrait Alive 阿里巴巴发布的EMO,一种音频驱动的AI肖像视频生成框架。通过输入单一的参考图像和语音音频,Emote Portrait Alive可以生成动态的、表情丰富的肖像视频。 Ai开源项目 2025年06月05日 18 点赞 0 评论 641 浏览
GEN3C GEN3C是由NVIDIA、多伦多大学和向量研究所联合开发的生成式视频模型,基于点云构建3D缓存,结合精确的相机控制和时空一致性技术,实现高质量视频生成。支持从单视角到多视角的视频创作,具备3D编辑能力,适用于动态场景和长视频生成。在新型视图合成、驾驶模拟、影视制作等领域有广泛应用前景。 AI项目与工具 2025年06月12日 23 点赞 0 评论 641 浏览
Vidalgo Vidalgo是一款基于人工智能技术的视频创作工具,专为TikTok、YouTube Shorts和Instagram Reels等平台设计。它提供多样化的音乐库、图片资源及视频模板,支持多语言操作,同时具备强大的AI功能,可自动生成引人注目的标题和标签,助力视频内容的高效传播。此外,Vidalgo还拥有无限创意探索和一键视频生成等功能,适用于内容创作者、营销团队及教育机构等多种应用场景。 AI项目与工具 2025年06月12日 78 点赞 0 评论 641 浏览
Vidu Q1 Vidu Q1是清华大学朱军教授团队研发的高可控视频生成模型,支持1080p高清视频生成,具备精准音效控制、多主体一致性调节、局部超分重建等功能。在多项国际评测中表现优异,包括VBench和SuperCLUE榜单均获第一。模型基于扩散模型与U-ViT架构,融合文本、图像和视频信息,适用于影视制作、广告宣传及动画创作等领域。 AI项目与工具 2025年06月12日 96 点赞 0 评论 641 浏览
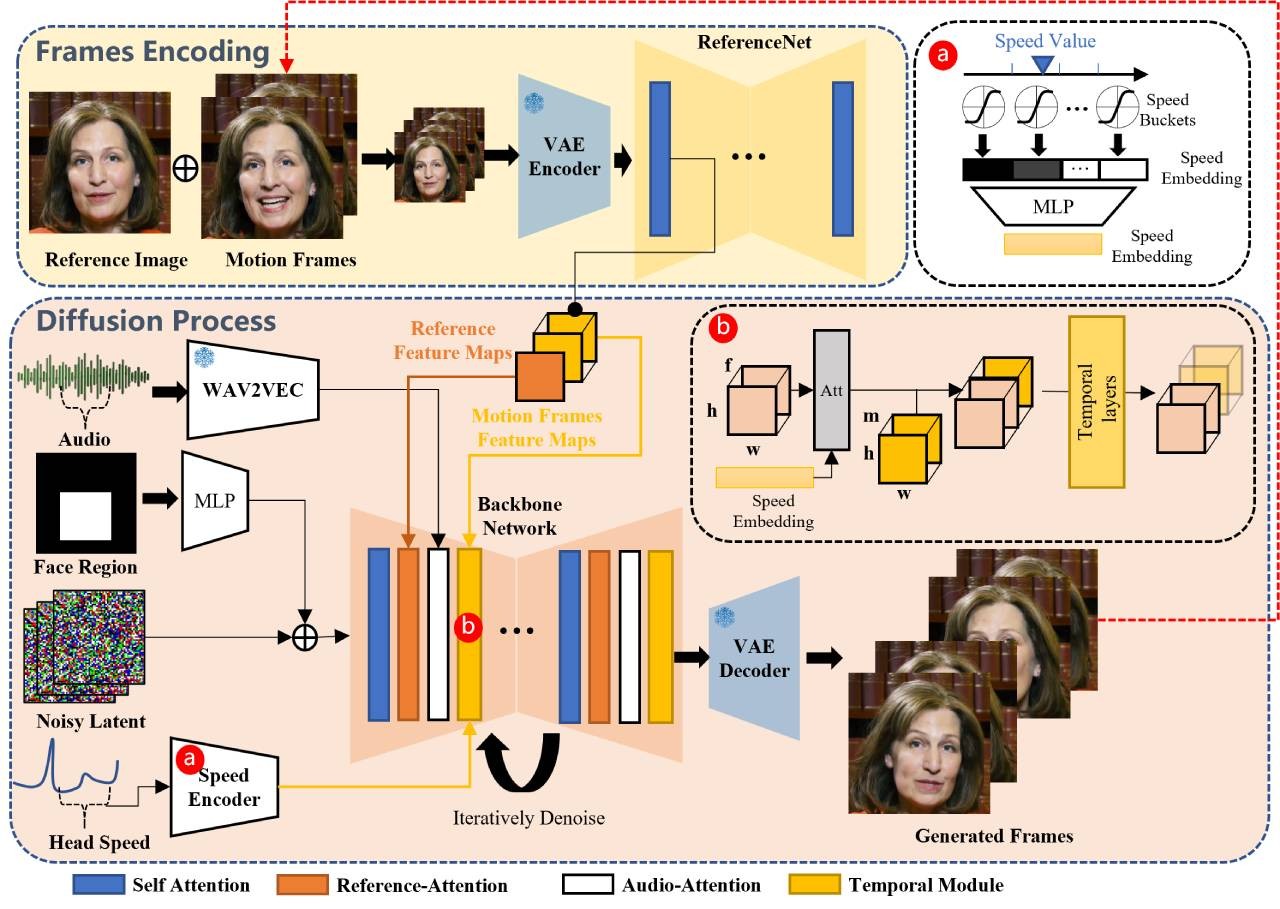
OmniHuman OmniHuman是字节跳动推出的多模态人类视频生成框架,基于单张图像和运动信号生成高逼真视频。支持音频、姿势及组合驱动,适用于多种图像比例和风格。采用混合训练策略和扩散变换器架构,提升生成效果与稳定性,广泛应用于影视、游戏、教育、广告等领域。 AI项目与工具 2025年06月12日 43 点赞 0 评论 641 浏览
Crayo AI Crayo AI是一款面向内容创作者的AI短视频生成工具,利用自然语言处理和计算机视觉技术,帮助用户一键生成适用于抖音、TikTok等平台的短视频。该工具提供多种功能,包括AI脚本生成、语音旁白、图像生成、视频编辑和自动字幕生成,简化了视频制作流程,使创作者能够更专注于创意和故事叙述,从而提升内容的吸引力和传播力。 AI项目与工具 2025年06月12日 24 点赞 0 评论 641 浏览
DICE DICE-Talk是由复旦大学与腾讯优图实验室联合开发的动态肖像生成框架,能够根据音频和参考图像生成具有情感表达的高质量视频。其核心在于情感与身份的解耦建模,结合情感关联增强和判别机制,确保生成内容的情感一致性与视觉质量。该工具支持多模态输入,具备良好的泛化能力和用户自定义功能,适用于数字人、影视制作、VR/AR、教育及心理健康等多个领域。 AI项目与工具 2025年06月11日 87 点赞 0 评论 639 浏览