Vision Parse Vision Parse 是一款开源工具,旨在通过视觉语言模型将 PDF 文件转换为 Markdown 格式。它具备智能识别和提取 PDF 内容的能力,包括文本和表格,并能保持原有格式与结构。此外,Vision Parse 支持多种视觉语言模型,确保解析的高精度与高速度。其应用场景广泛,涵盖学术研究、法律文件处理、技术支持文档以及电子书制作等领域。 AI项目与工具 2025年06月12日 72 点赞 0 评论 625 浏览
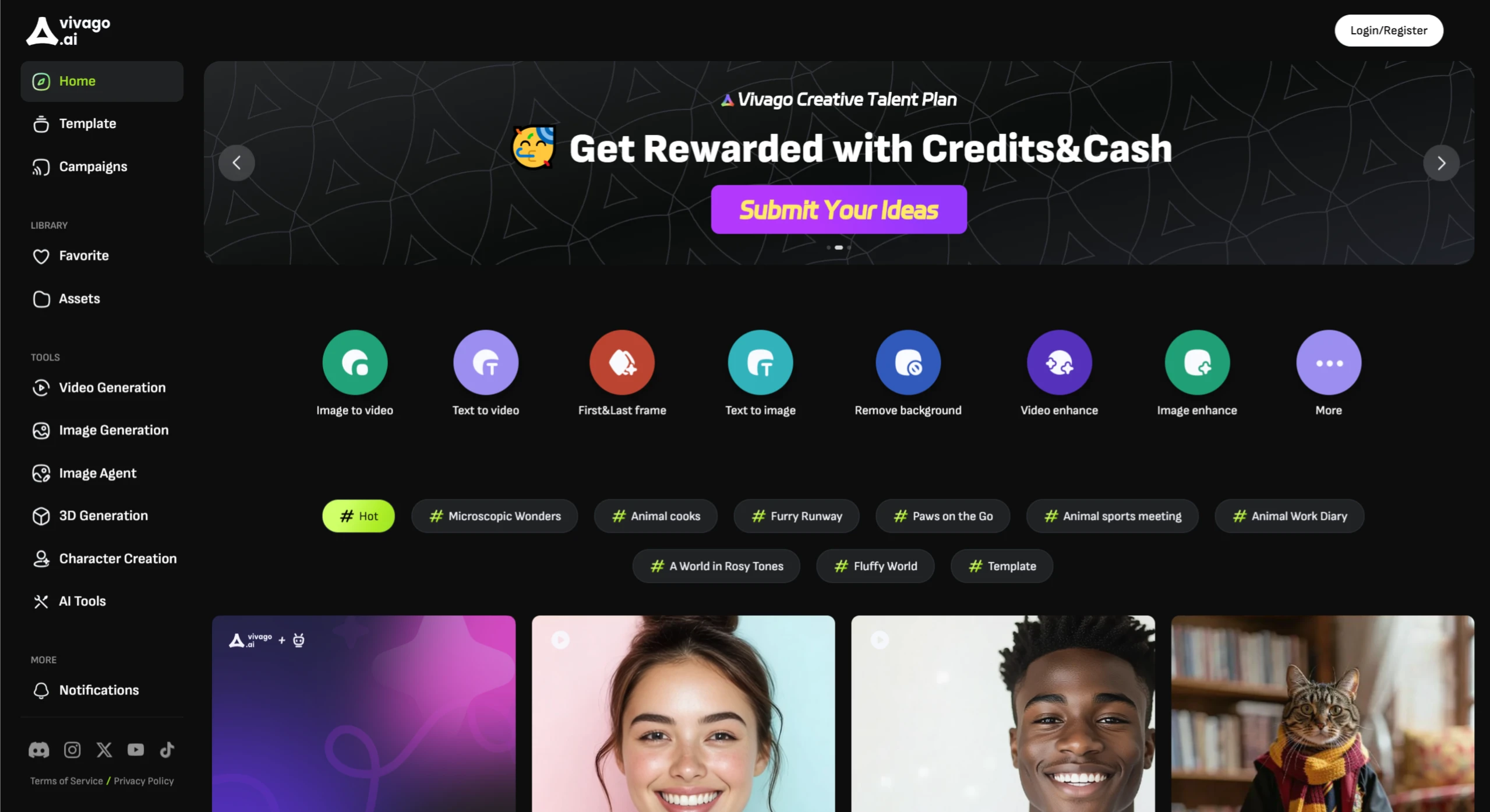
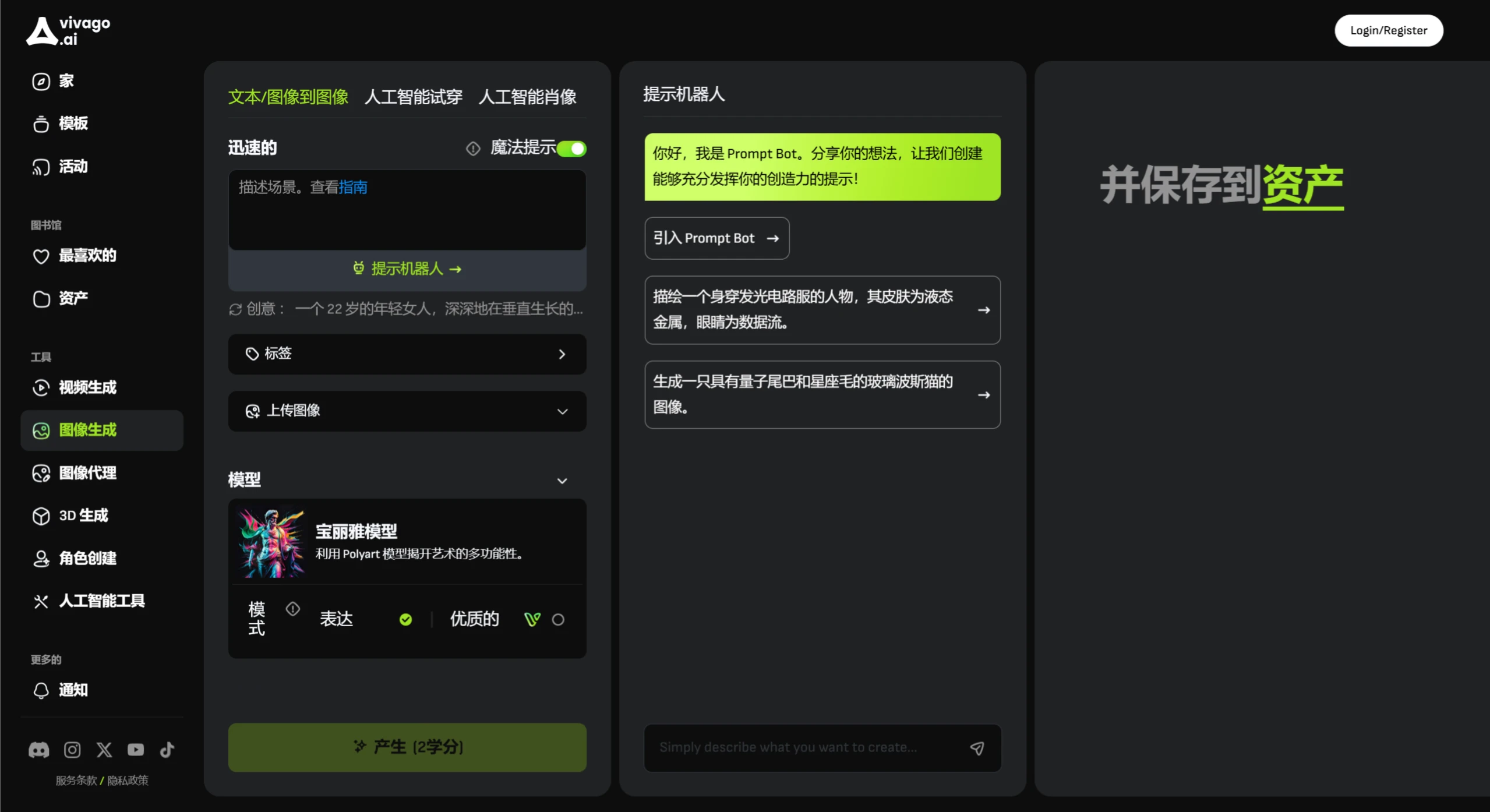
Vivago AI 北京智象未来科技有限公司面向全球市场推出的一款综合性在线 AI 创作平台,提供视频生成、图片生成、图片agent编辑,数字人生成,3D模型等功能。 Ai绘画生成 2025年06月05日 12 点赞 0 评论 625 浏览
赤兔Chitu Chitu(赤兔)是清华大学与清程极智联合开发的高性能大模型推理引擎,支持多种GPU及国产芯片,打破对特定硬件的依赖。其具备全场景部署能力,支持低延迟、高吞吐、小显存优化,并在性能上优于部分国外框架。适用于金融风控、智能客服、医疗诊断、交通优化和科研等领域,提供高效、稳定的推理解决方案。 AI项目与工具 2025年06月12日 25 点赞 0 评论 626 浏览
文鳐MaaS 文鳐MaaS是一个综合性的AI模型训练平台,它通过提供易操作的界面和强大的自监督学习能力,使用户能够根据自己的特定需求快速定制和部署AI模型。 创作工具 2026年06月24日 0 点赞 0 评论 626 浏览
汉语新解TextHuman 一个基于李继刚Prompt模板的项目,汉语新解对中文名词进行二次翻译,并生成美观的图像。TextHuman提供智能词汇解释,用户可以输入任何汉语词汇,获得AI生成的新颖解释。 剧本文案 2025年06月05日 30 点赞 0 评论 626 浏览
LibreChat 一个开源多模态AI对话平台,它支持与多种AI模型服务的集成,包括OpenAI、Azure、Anthropic和Google等。 AI写作对话 2025年06月05日 92 点赞 0 评论 626 浏览
Vidu 1.5 Vidu 1.5是一款基于多模态视频大模型的AI生成工具,支持参考生视频、图生视频和文生视频生成,通过精准的语义理解能力,在30秒内完成高质量视频创作,适用于影视、动漫、广告等多行业场景,助力创作者高效产出多样化内容。 AI项目与工具 2025年06月12日 80 点赞 0 评论 626 浏览
olmOCR olmOCR 是一款开源 PDF 文档处理工具,结合文档锚定技术和 Qwen2-VL-7B-Instruct 模型,可高效提取结构化文本并保留原始布局。支持多种文档类型,具备大规模批量处理能力和低成本优势,适用于学术研究、法律文件处理、企业文档管理及数字图书馆建设等多个场景。其开源特性与可扩展性也增强了用户的使用灵活性。 AI项目与工具 2025年06月12日 47 点赞 0 评论 627 浏览
百度灵医Bot 百度灵医Bot作为百度推出的医疗大模型应用,通过其强大的语言处理能力和专业医疗知识库,为用户提供了全面、安全、智能的医疗健康服务。 创作工具 2026年06月24日 0 点赞 0 评论 627 浏览