GOT-OCR2.0 创新的OCR模型,它通过先进的技术提供了精准、高效的OCR解决方案。无论是文档数字化、场景文本识别还是票据处理等应用场景,GOT-OCR 2.0都能提供强大的支持。 Ai平台模型 1970年01月01日 0 点赞 0 评论 503 浏览
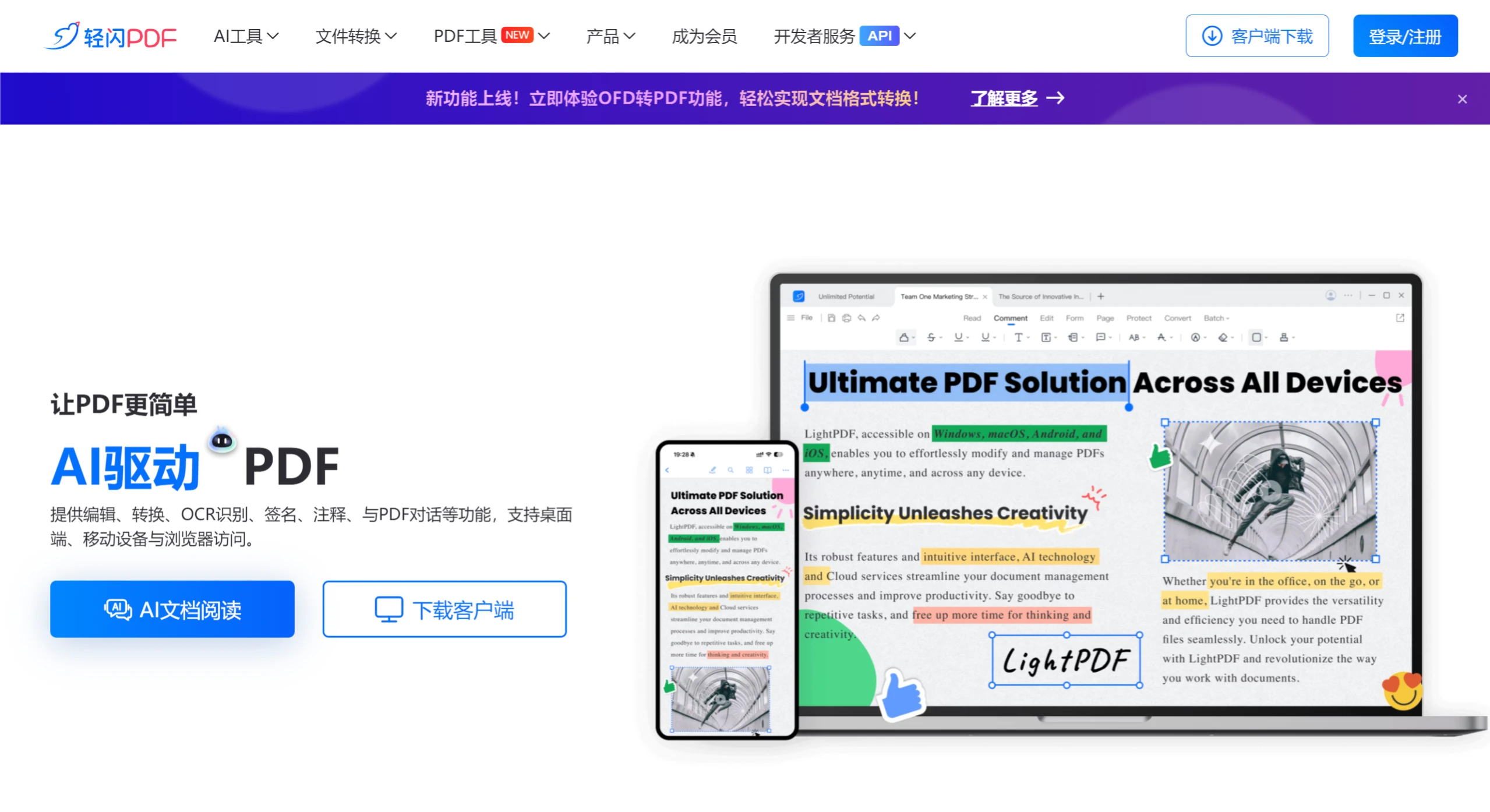
Marker Marker 是一款开源的高精度文档转换工具,支持 PDF、Word 等多种格式向 Markdown、JSON 和 HTML 的转换。它利用深度学习技术自动去除干扰元素,支持多语言处理,具备表格、代码块、公式识别及图像提取等功能,适用于学术研究、技术文档、教育资料等多种场景。同时支持硬件加速和批量处理,提升转换效率与用户体验。 AI项目与工具 2025年06月12日 26 点赞 0 评论 503 浏览
媒小三 媒小三 ,实用的新媒体工具大全,提供各种实用新媒体工具,如:AI配音,视频解析,短视频下载,文案提取,文章改写,标题生成等功能,帮助新媒体人一站式快捷操作。 Ai办公效率 2025年06月05日 46 点赞 0 评论 502 浏览
Kimi Kimi-VL是月之暗面推出的轻量级多模态视觉语言模型,支持图像、视频、文档等多种输入形式。其基于轻量级MoE架构和原生分辨率视觉编码器,具备强大的图像感知、数学推理和OCR能力。在长上下文(128K)和复杂任务中表现优异,尤其在多模态推理和长视频理解方面超越同类模型。适用于智能客服、教育、医疗、内容创作等多个领域。 AI项目与工具 2025年06月11日 30 点赞 0 评论 498 浏览
AI Comic Translate 只需上传您想要翻译的漫画图片,用户只需上传您想要翻译的漫画图片,AI Comic Translate将自动识别文本并在几分钟内生成高质量的翻译。 Ai图片处理 2025年06月05日 39 点赞 0 评论 496 浏览
parsio Parsio是一款利用AI技术的文档解析工具,支持从PDF、电子邮件及发票等多种文档中自动提取结构化数据。它提供PDF解析与OCR功能,支持多语言识别和表格提取,适用于业务流程优化、客户关系管理及财务管理等多个领域,帮助企业提高效率并减少错误。 AI项目与工具 2025年06月12日 21 点赞 0 评论 488 浏览
OmniAI OmniAI是一款基于OCR与NLP技术的智能文档处理平台,支持多种文件格式的数据提取与分类。其核心功能包括批量处理、结构化数据输出以及自定义模型开发,适用于财务审计、客户服务、法律合规、医疗健康及保险理赔等多个领域,为企业提供高效的文档智能化解决方案。 AI项目与工具 2025年06月12日 79 点赞 0 评论 484 浏览
Versatile Versatile-OCR-Program是一款开源多模态OCR工具,支持从教育材料中提取文本、公式、表格等结构化数据,输出为JSON或Markdown格式,准确率高达90%-95%。它基于DocLayout-YOLO、Google Vision和MathPix等技术,支持多语言处理,适用于教育数据集制作、教学辅助、AI模型训练及个人学习等场景。 AI项目与工具 2025年06月11日 77 点赞 0 评论 481 浏览