音频








EchoMimicV2
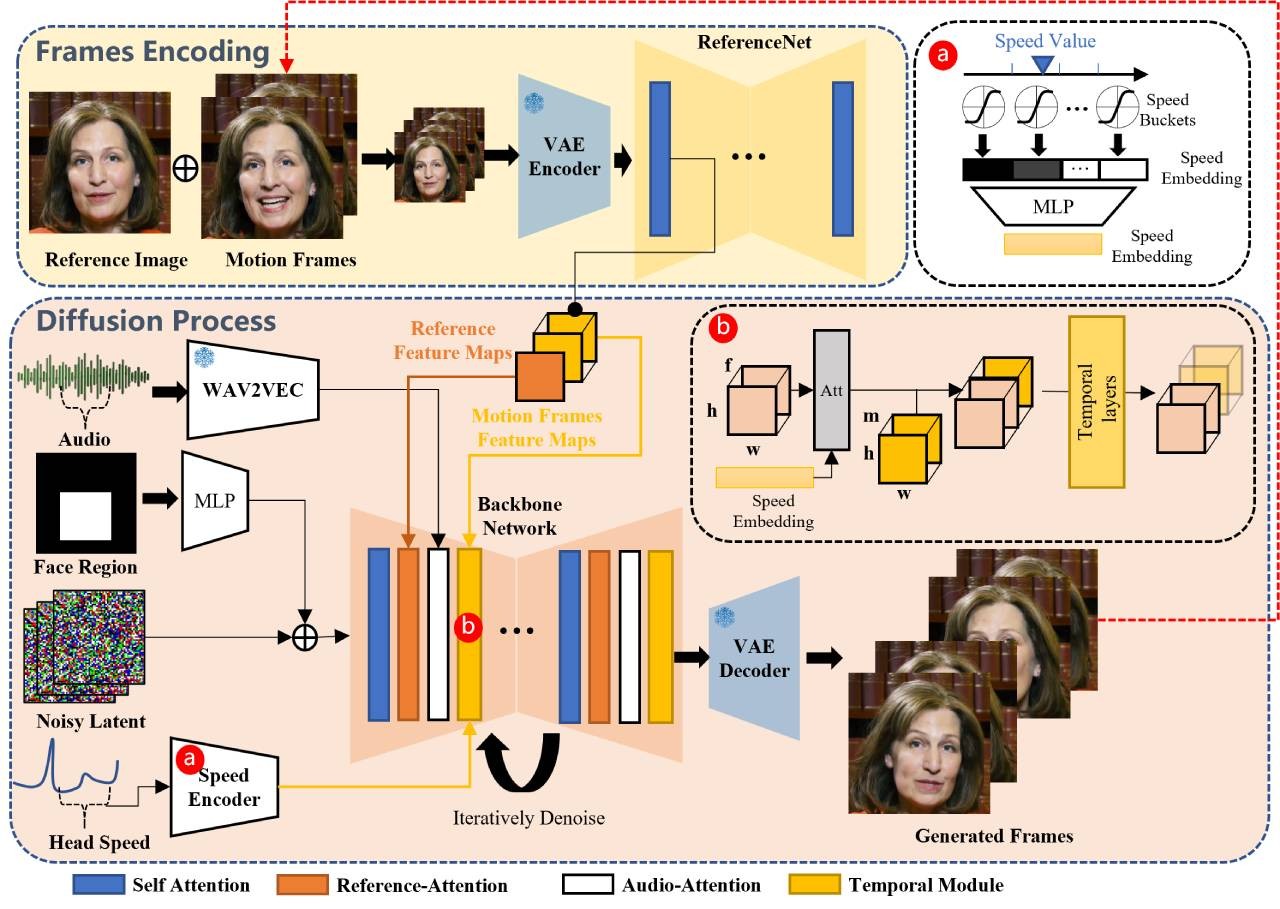
EchoMimicV2是一款由阿里巴巴蚂蚁集团研发的AI数字人动画生成工具,能够基于参考图片、音频剪辑及手部姿势序列生成高质量的半身动画视频。它支持多语言(中英双语)输入,并通过音频-姿势动态协调、头部局部注意力及特定阶段去噪损失等技术手段显著提高了动画的真实度与细节表现力,适用于虚拟主播、在线教育、娱乐游戏等多个领域。


