UniFab AI 一款可以通过AI算法增强视频和音频质量工具。UniFab AI针对的用户群体主要有老旧视频想要修复和增强、对视频播放有更高要求的影音爱好者。 视频剪辑 2025年06月05日 45 点赞 0 评论 761 浏览
Alphy 一个由AI驱动提供在线和本地音频内容的转录、摘要和问答服务的平台,包括YouTube视频。Alphy帮助用户快速高效地从音频和音频视听媒体中提取有价值的信息。 Ai语音工具 2025年06月05日 45 点赞 0 评论 758 浏览
Suno AI Suno AI 是由 Anthropic 公司开发的一款 AI 音乐和语音生成工具。 仅使用文本提示即可生成高质量的歌声、乐器和完整的音乐作品。 Ai语音工具 2025年06月05日 34 点赞 0 评论 756 浏览
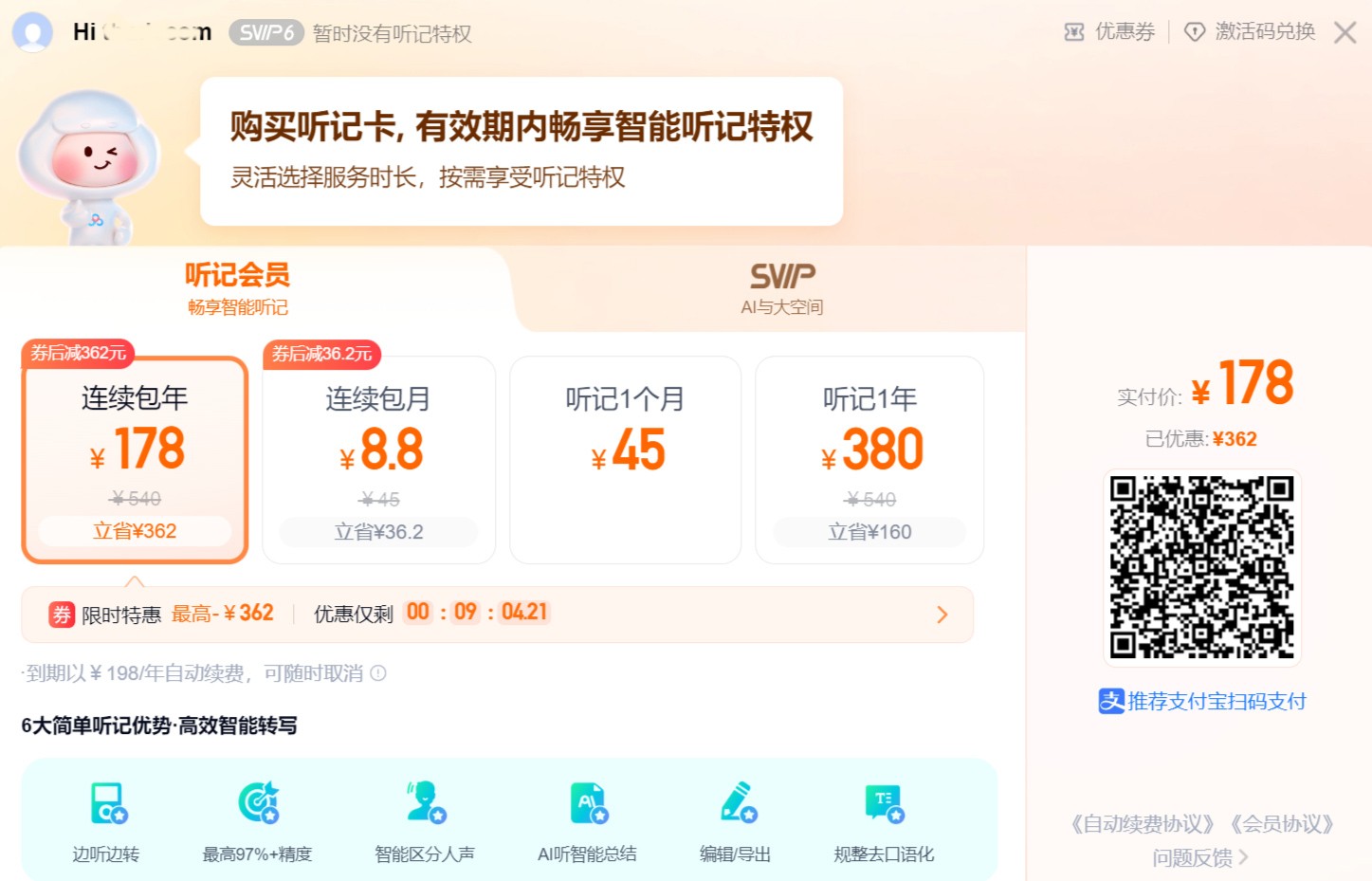
简单听记 百度网盘推出的一款AI语音转文字工具,简单听记能够帮你将音频内容转化为文字,还能进一步把这些文字提炼总结,帮你节省很多时间。 Ai语音工具 2025年06月05日 94 点赞 0 评论 756 浏览
EmotiVoice EmotiVoice是网易有道推出的开源文本到语音系统,支持中英文及2000+音色,能根据提示生成带情感的语音。具备情感合成、语音克隆、多语言支持等功能,提供Web界面和API接口,适用于有声读物、智能助手、教育、客服等场景,技术上支持高效部署与模型微调。 AI项目与工具 2025年06月12日 30 点赞 0 评论 752 浏览
OpenMusic OpenMusic是一款基于QA-MDT技术的文生音乐工具,支持从文本生成高质量音乐作品,具备质量感知训练、多样化风格生成及复杂推理能力。它广泛应用于音乐制作、多媒体内容创作、音乐教育等领域,同时提供音频编辑与处理功能,旨在提升音乐创作效率和质量。 AI项目与工具 2025年06月12日 87 点赞 0 评论 751 浏览
Liner.ai Liner.ai 是一款面向非专业程序员和数据科学家的机器学习工具,通过简单的点击操作即可训练模型,无需编写代码。该工具提供多种项目模板,涵盖图像、文本、音频和视频分类,以及对象检测和图像分割等任务。Liner.ai 支持在 CPU 上快速训练模型,并可在本地完成训练以保护数据隐私。此外,该工具还允许用户轻松地将模型导出到多个平台,适合初学者和专业人士使用。 AI项目与工具 2025年06月12日 96 点赞 0 评论 751 浏览