语音


OmniTalker
OmniTalker 是一款由阿里巴巴开发的实时多模态交互技术,支持文本、图像、音频和视频的同步处理,并能生成自然流畅的语音响应。其核心技术包括 Thinker-Talker 架构和 TMRoPE 时间对齐技术,实现音视频精准同步与高效流式处理。适用于智能语音助手、内容创作、教育、客服及工业质检等场景,具有高实时性与稳定性。

Parakeet TDT 0.6B
Parakeet TDT 0.6B 是一款由英伟达开发的开源自动语音识别(ASR)模型,采用 FastConformer 和 TDT 架构,具备高速转录、高精度识别、歌词转录、文本格式化等功能。模型在 Hugging Face Open ASR Leaderboard 中表现优异,实时因子高达 3386,适用于会议记录、法律医疗、字幕生成及音乐索引等多种场景。



AI Chinese
AI Chinese是一款利用AI技术打造的双语中文学习平台,提供个性化的在线教学服务。其核心功能包括AI模拟教学、双语教学支持、互动练习、语音识别与校正及提问解答等模块,能够满足个人自学、语言学校辅助教学、企业培训等多种应用场景需求。凭借自研中文知识图谱和精准语音反馈,该平台致力于帮助不同语言背景的学习者高效掌握中文。


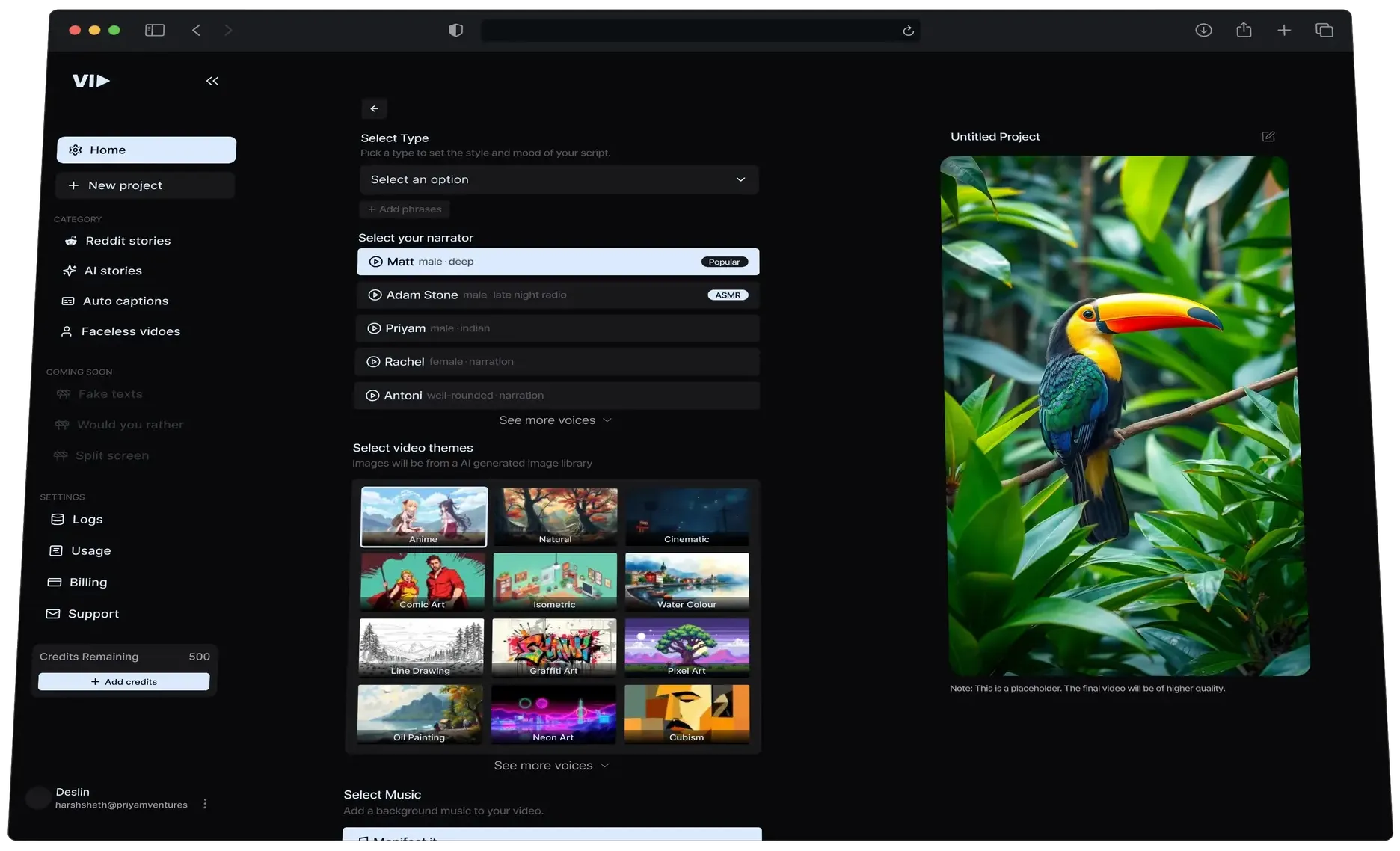
Narration Box
Narration Box是一种语音合成服务,用户可以创建画外音、旁白、有声读物、音频页面、播客等。它拥有超过700个人工智能增强的仿人叙述者,支持20多种语言,功能强大的语音编辑器,...

