DreamVideo DreamVideo-2是一款由复旦大学和阿里巴巴集团等机构共同开发的零样本视频生成框架,能够利用单一图像及界定框序列生成包含特定主题且具备精确运动轨迹的视频内容。其核心特性包括参考注意力机制、混合掩码参考注意力、重加权扩散损失以及基于二值掩码的运动控制模块,这些技术共同提升了主题表现力和运动控制精度。DreamVideo-2已在多个领域如娱乐、影视制作、广告营销、教育及新闻报道中展现出广泛应用前 AI项目与工具 2025年06月12日 65 点赞 0 评论 558 浏览
绘蛙·多图成片 绘蛙·多图成片是一款基于AI技术的视频生成工具,通过上传2-4张连贯图片并配合文字描述,快速生成高质量视频。支持多种视频尺寸,具备智能文案生成能力,适用于创意视频、广告、电商展示等多种场景,显著降低视频制作门槛和成本。 AI项目与工具 2025年06月12日 18 点赞 0 评论 559 浏览
DreaMoving DreaMoving是一个基于扩散模型的人类视频生成框架,由阿里巴巴集团研究团队开发。该框架通过视频控制网络(Video ControlNet)和内容引导器(Content Guider)实现对人物动作和外观的精确控制,允许用户通过文本或图像提示生成个性化视频内容。其主要功能包括定制化视频生成、高度可控性、身份保持、多样化的输入方式以及易于使用的架构设计。DreaMoving广泛应用于影视制作、游 AI项目与工具 2024年01月01日 93 点赞 0 评论 559 浏览
ImageToVideo AI ImageToVideo AI 是一款基于人工智能的图像转视频工具,能够将静态图片转化为动态视频。通过智能分析图像内容并结合用户输入的文本指令,可添加动画、转场、音乐、字幕等元素,生成高质量、富有表现力的视频。支持多种格式输出,提供丰富的模板和自定义选项,适用于个人创作、内容制作、教育及广告等多种场景,提升视频制作效率与视觉效果。 AI项目与工具 2025年06月12日 80 点赞 0 评论 560 浏览
Hallo2 Hallo2是一款由复旦大学、百度公司和南京大学合作开发的音频驱动视频生成模型。它能够将单张图片与音频结合,并通过文本提示调节表情,生成高分辨率4K视频。Hallo2采用了补丁下降、高斯噪声等数据增强技术,提升了视频的视觉一致性和时间连贯性,同时通过语义文本标签提高了生成内容的可控性与多样性。该模型适用于电影、游戏、虚拟助手等多个领域,展现出强大的内容生成能力。 AI项目与工具 2025年06月12日 80 点赞 0 评论 560 浏览
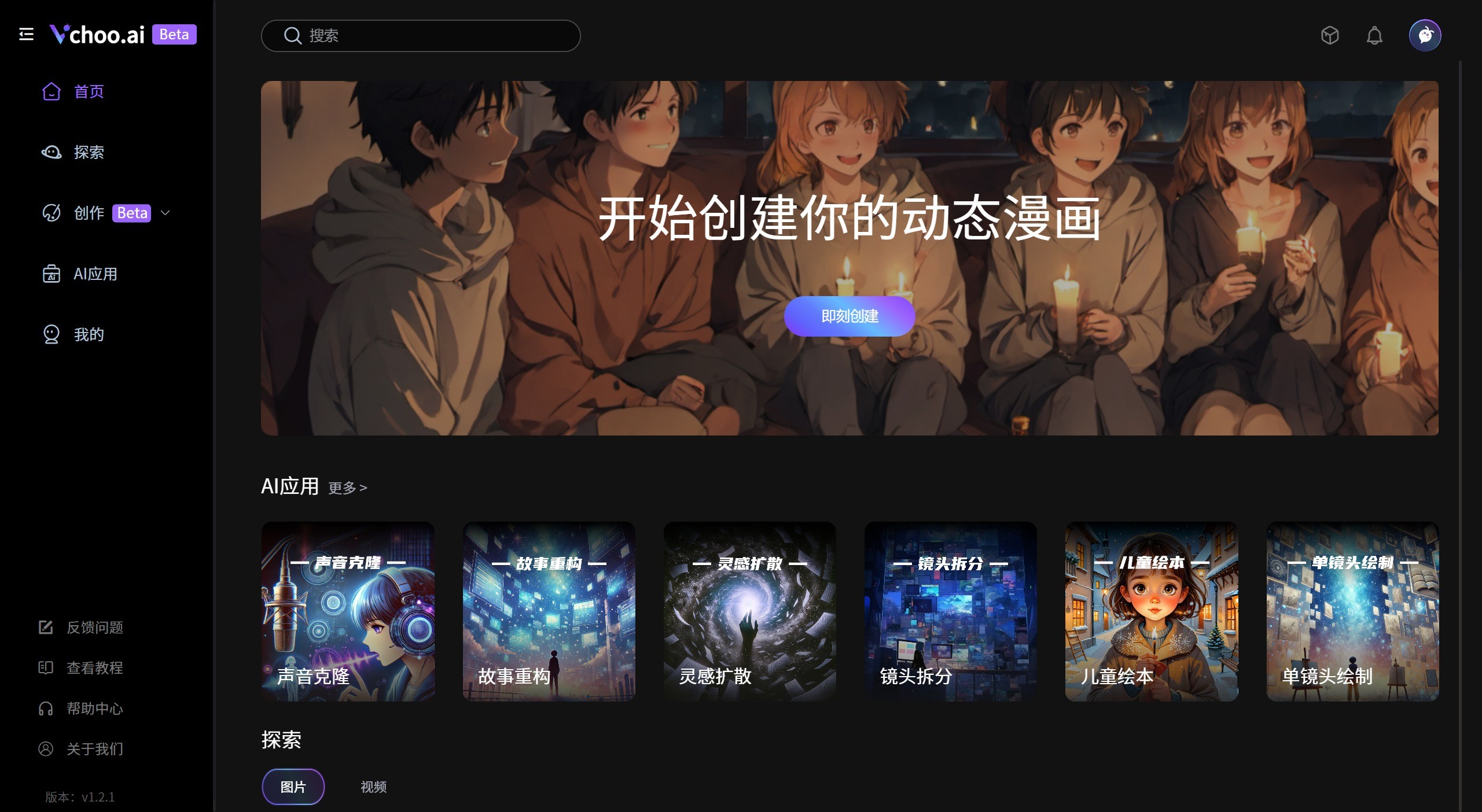
Vchoo.ai 一个故事转视频的AI故事短片创作AIGC工具,Vchoo.ai简化从故事创作到视频生成的过程,丰富的故事题材、多元的画面风格、稳定可控的角色和场景,轻松地将故事视觉化。 Ai视频生成 2025年06月05日 97 点赞 0 评论 561 浏览
ToonCrafter ToonCrafter是一个展示平台,它利用先进的生成对抗网络(GAN)技术,将用户的原始动漫帧转化为一系列风格一致、过渡自然的画面。 Ai视频生成 2026年06月23日 0 点赞 0 评论 562 浏览
Deepfakes Creator Deepfakes Creator,可以通过文本输入生成逼真的会说话的真人视频。用户只需要上传想要化身模仿的人的照片,并写一个剧本,工具就能创建出逼真的人物化身视频,模拟人物说话。 Ai开源项目 2025年06月05日 62 点赞 0 评论 562 浏览
TIP TIP-I2V是一个包含大量真实文本和图像提示的数据集,专为图像到视频生成领域设计。它涵盖了超过170万个独特的提示,并结合多种顶级图像到视频生成模型生成的视频内容。该数据集支持用户偏好分析、模型性能评估以及解决错误信息传播等问题,有助于推动图像到视频生成技术的安全发展。 AI项目与工具 2025年06月12日 23 点赞 0 评论 563 浏览
FlashVideo FlashVideo是由字节跳动团队研发的高分辨率视频生成框架,采用两阶段方法优化计算效率。第一阶段在低分辨率下生成高质量内容,第二阶段通过流匹配技术提升至1080p,仅需4次函数评估。其特点包括高效计算、细节增强、快速预览及多场景应用,适用于广告、影视、教育等领域。 AI项目与工具 2025年06月12日 26 点赞 0 评论 563 浏览