Proface Proface 是一款 AI 照片和头像生成器,可以在不到 40 小时内为您创建 24+ 张专业照片,您需要做的就是上传 10-25 张自己的照片。 Ai图片处理 2025年06月05日 85 点赞 0 评论 587 浏览
NobodyWho NobodyWho是一款专为Godot游戏引擎设计的AI插件,支持本地运行大型语言模型(LLM),提供高效、安全的互动叙事功能。其核心特性包括本地化处理、GPU加速、多上下文支持、流式输出、采样器调节、语义嵌入、工具调用及记忆功能。适用于互动小说、动态对话系统及多线叙事等场景,帮助开发者构建更真实、灵活的游戏内容。 AI项目与工具 2025年06月12日 88 点赞 0 评论 587 浏览
救救图片 该AI图片处理工具提供去水印、抠图、去马赛克、无损放大、图片修复及生成相似图等功能,基于先进算法实现高效精准的图像编辑。支持多种格式下载,操作简便,适用于设计师、电商卖家及内容创作者,广泛应用于素材优化、商品展示和内容制作等领域。 AI项目与工具 2025年06月12日 41 点赞 0 评论 586 浏览
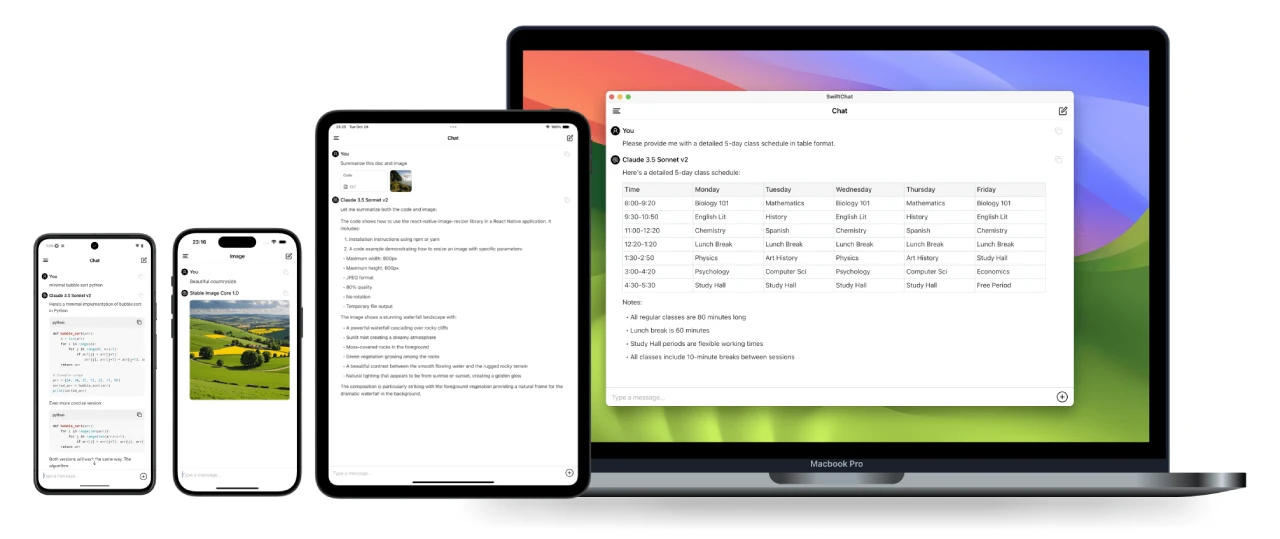
SwiftChat 一款基于React Native开发的快速、安全、跨平台聊天应用,支持实时流式聊天功能和Markdown语法,还可以生成AI图像,兼容DeepSeek、Amazon Bedrock、Ollama和OpenAI等模型。 Ai开源项目 2025年06月05日 44 点赞 0 评论 586 浏览
Inworld AI Inworld AI是一个综合性的AI游戏开发平台,它通过提供先进的NPC逻辑、互动剧情设计工具、实时AI反应和自然语音生成等功能,极大地增强了游戏的沉浸感和互动性。 创作工具 2026年06月25日 0 点赞 0 评论 586 浏览
Bria.ai 一个使用AI 大规模创建和自定义图像和视频的平台。无论您是需要删除不需要的对象、找到完美的图像、修改现有图像还是文字创建独特的背景。 图片处理 2025年06月05日 22 点赞 0 评论 585 浏览