TransPixar TransPixar是由多所高校及研究机构联合开发的开源文本到视频生成工具,基于扩散变换器(DiT)架构,支持生成包含透明度信息的RGBA视频。该技术通过alpha通道生成、LoRA微调和注意力机制优化,实现高质量、多样化的视频内容生成。适用于影视特效、广告制作、教育演示及虚拟现实等多个领域,为视觉内容创作提供高效解决方案。 AI项目与工具 2025年06月12日 17 点赞 0 评论 882 浏览
START START是由阿里巴巴集团与中科大联合研发的工具增强型推理模型,通过集成外部工具(如Python代码执行器)提升大型语言模型的推理能力。其核心在于“Hint-infer”和“Hint-RFT”技术,结合长链推理与工具调用,显著提高复杂数学、科学问题及编程任务的准确性和效率。该模型具备自我调试、多策略探索和自学习能力,适用于科研、教育、编程等多个领域,是首个开源的长链推理与工具集成模型。 AI项目与工具 2025年06月12日 72 点赞 0 评论 882 浏览
OpenAI o4 OpenAI o4-mini 是一款高性能、低成本的小型推理模型,专为快速处理数学、编程和视觉任务优化。它具备多模态能力,可结合图像与文本进行推理,并支持工具调用以提高准确性。在多项基准测试中表现优异,尤其在数学和编程领域接近完整版模型。适用于教育、数据分析、软件开发及内容创作等多个场景,是高效率与性价比兼备的AI工具。 AI项目与工具 2025年06月11日 27 点赞 0 评论 882 浏览
Skywork R1V Skywork R1V是昆仑万维推出的首个工业级多模态思维链推理模型,具备强大的视觉链式推理能力,可处理数学问题、科学现象分析、医学影像诊断等复杂任务。其技术基于文本推理能力的多模态迁移与混合式训练方法,在多项基准测试中表现优异。模型开源,适用于教育、医疗、科研、内容审核等多个领域,推动多模态人工智能的发展。 AI项目与工具 2025年06月12日 80 点赞 0 评论 882 浏览
UNO UNO是字节跳动推出的AI图像生成框架,支持单主体和多主体图像生成,解决多主体一致性难题。采用扩散变换器和渐进式跨模态对齐技术,结合通用旋转位置嵌入(UnoPE),实现高一致性与可控性。适用于虚拟试穿、产品设计、创意设计等多个领域,具备强大泛化能力,已开源并提供完整技术文档。 AI项目与工具 2025年06月11日 23 点赞 0 评论 883 浏览
DeepSeek V3 DeepSeek V3是一款由幻方量化旗下的深度求索公司开源的AI模型,拥有6850亿参数,采用混合专家架构。它在多语言编程、长文本处理和对话交互方面表现出色,能够生成高质量代码、优化现有代码、协助调试、生成文本、分析文本、润色文本,并支持自然对话和多轮对话。此外,它在多个基准测试中表现出色,包括编程、数学、推理等领域。 AI项目与工具 2025年06月12日 53 点赞 0 评论 884 浏览
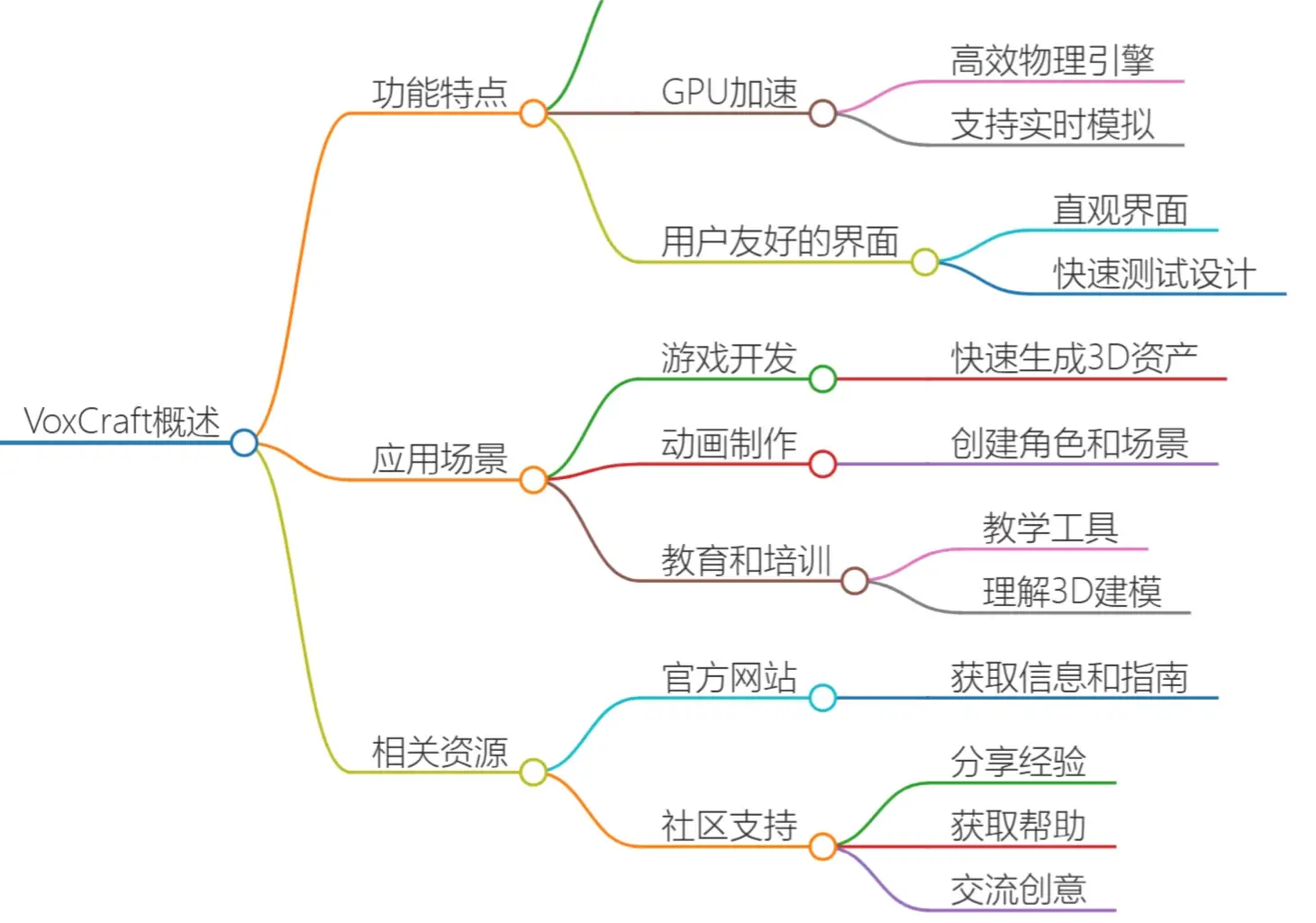
VoxCraft Ai 北京生数科技有限公司开发的一款强大的AI生成3D工具,VoxCraft Ai基于底层通用多模态大模型,具备优越的多模态生成能力。 3D&游戏 2025年06月05日 22 点赞 0 评论 884 浏览
Skywork Skywork-Reward 是昆仑万维推出的一系列高性能奖励模型,包括 Skywork-Reward-Gemma-2-27B 和 Skywork-Reward-Llama-3.1-8B,主要用于优化大语言模型的训练过程。这些模型通过提供奖励信号,帮助模型理解和生成符合人类偏好的内容。Skywork-Reward 在对话、安全性和推理任务中表现出色,并且在 RewardBench 评估基准上名列前 AI项目与工具 2025年06月12日 32 点赞 0 评论 884 浏览
MinMo MinMo是阿里巴巴通义实验室推出的多模态语音交互大模型,具备高精度语音识别与生成能力。支持情感表达、方言转换、音色模仿及全双工交互,适用于智能客服、教育、医疗等多个领域,提升人机对话的自然度与效率。 AI项目与工具 2025年06月12日 59 点赞 0 评论 884 浏览
FinRobot FinRobot是一款开源的AI代理平台,专注于金融领域的应用,基于大型语言模型(LLMs)构建能够执行复杂分析和决策的专业金融AI代理。平台通过金融思维链(CoT)提示功能提升分析能力,并通过开源方式促进AI在金融决策中的广泛应用。架构涵盖金融AI代理层、金融LLM算法层、LLMOps和DataOps层以及多源LLM基础模型层,支持市场预测、文档分析及交易策略等多种金融专业AI代理。 AI项目与工具 2025年06月12日 74 点赞 0 评论 885 浏览