Outspeed Outspeed 是一个专注于实时语音和视频 AI 应用开发的平台,提供强大的流媒体处理、低延迟推理、即时部署等功能,支持企业级合规标准。其核心特性包括灵活的模型定制、全面的 SDK 支持以及高效的应用监控工具,广泛应用于客户服务、教育、医疗保健、娱乐、安全监控和质量控制等领域。 AI项目与工具 2025年06月12日 41 点赞 0 评论 834 浏览
TrackVLA TrackVLA是银河通用推出的端到端导航大模型,具备纯视觉环境感知、语言指令驱动、自主推理和零样本泛化能力。它能在复杂环境中自主导航、灵活避障,并根据自然语言指令识别和跟踪目标对象。无需提前建图,适用于多种场景,如陪伴服务、安防巡逻、物流配送等,为具身智能商业化提供支撑,推动机器人走向日常生活。 AI项目与工具 2025年06月11日 79 点赞 0 评论 835 浏览
Google Bard Google 推出的一款对话式AI工具,Bard 可以帮助您完成各种任务,例如编写、编码、调试和解释代码。您还可以与 Bard 进行有趣的对话,探索它的创造力和幽默感。 Ai平台模型 2025年06月05日 54 点赞 0 评论 835 浏览
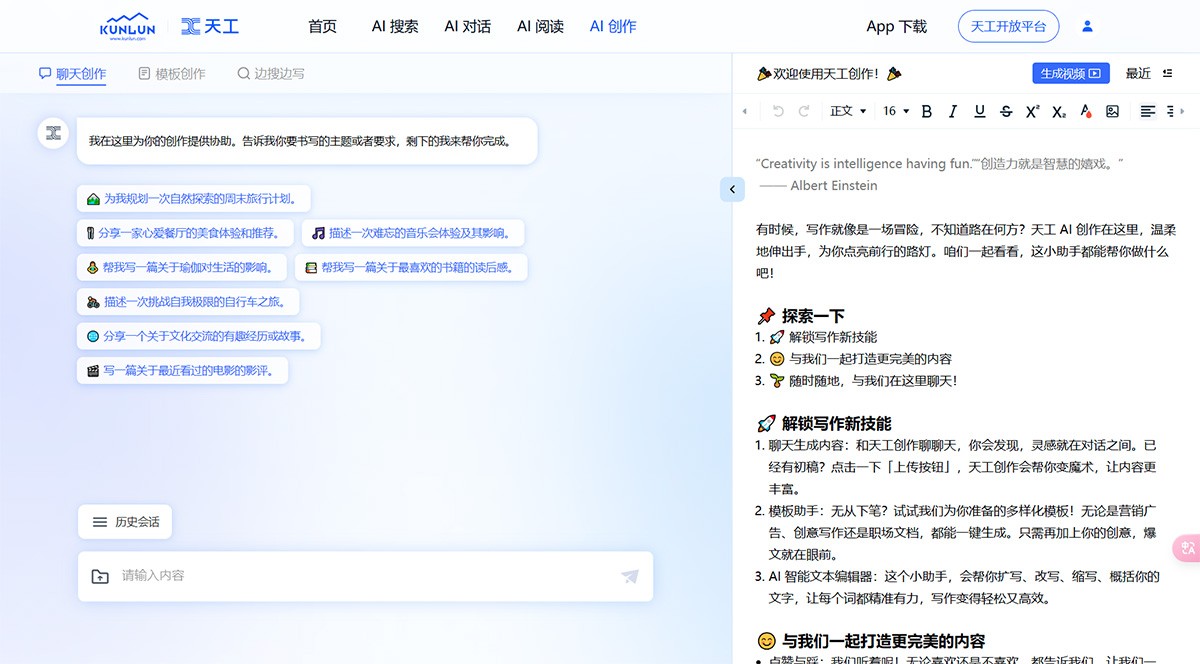
天工大模型 有时候,写作就像是一场冒险,不知道路在何方?天工大模型天工AI创作在这里,温柔地伸出手,为你点亮前行的路灯。咱们一起看看,这小助手都能帮你做什么吧! Ai平台模型 2025年06月05日 99 点赞 0 评论 835 浏览
Voila Voila是一款开源的端到端语音大模型,支持实时语音交互与多轮对话,具备高保真、低延迟的音频处理能力。集成语音与语言建模功能,支持百万级预设声音及个性化定制,适用于语音助手、角色扮演、语音翻译等场景。采用多尺度Transformer架构,提升语音理解与生成质量,降低开发成本,提高通用性与灵活性。 AI项目与工具 2025年06月11日 60 点赞 0 评论 836 浏览
InvSR InvSR是一款基于扩散模型逆过程开发的图像超分辨率工具,通过深度噪声预测器和灵活采样机制,从低分辨率图像恢复高质量高分辨率图像。它支持多种应用场景,包括文化遗产保护、视频监控、医疗成像及卫星影像分析,同时兼顾计算效率与性能表现。 AI项目与工具 2025年06月12日 14 点赞 0 评论 836 浏览
HumanOmni HumanOmni 是一款面向人类中心场景的多模态大模型,融合视觉与听觉信息,具备情感识别、面部描述、语音理解等功能。基于大量视频与指令数据训练,采用动态权重调整机制,支持多模态交互与场景理解。适用于影视分析、教育、广告及内容创作等领域,具备良好的可扩展性和灵活性。 AI项目与工具 2025年06月12日 92 点赞 0 评论 836 浏览
光语大模型 无限光年公司发布的一款结合大语言模型与符号推理的AI大模型,光语大模型目的是解决大模型在行业应用中的幻觉问题,提高了模型的可信度和专业性。 Ai平台模型 2025年06月05日 89 点赞 0 评论 836 浏览
Ultravox Ultravox 是一种多模态大型语言模型(LLM),能够直接处理文本和语音输入,无需额外的语音识别步骤。其核心技术包括多模态投影器,用于将音频数据转换为高维空间表示,显著提升语音理解和处理效率。该模型支持实时语音对话、多语言扩展及领域特定知识的学习,适用于智能客服、虚拟助手、语言学习、实时翻译及教育等领域。 AI项目与工具 2025年06月12日 51 点赞 0 评论 836 浏览
Llama 3.3 Llama 3.3是一款由Meta AI开发的70B参数大型多语言预训练语言模型,支持英语、德语、法语等8种语言的输入输出。它具备长上下文窗口、高效运行和低成本的特点,可与第三方工具集成,广泛应用于聊天机器人、客户服务、语言翻译、内容创作及教育等领域。 AI项目与工具 2025年06月12日 71 点赞 0 评论 836 浏览