AI Studios AI Studios是一个一站式AI视频生成平台,它通过提供多样化的AI工具和模板,使用户能够轻松创建专业质量的视频内容。无论是初学者还是专业人士,都能利用这个平台提高视频制作的效... Ai视频生成 2026年06月23日 0 点赞 0 评论 799 浏览
中科相生 – 数字克隆人 中科相生作为一个数字克隆人生产力工具,通过其先进的AI技术和用户友好的界面,为用户提供了一个高效、个性化的视频制作平台。 创作工具 2026年06月23日 0 点赞 0 评论 795 浏览
WorldDreamer WorldDreamer 是一种基于 Transformer 的通用世界模型,具备理解与预测物理世界动态变化的能力,专注于视频生成任务。它支持多种应用场景,包括文本到视频、图像到视频、视频编辑和动作序列生成,利用视觉 Token 化、Transformer 架构和多模态提示技术,实现了高效且高质量的视频生成。 AI项目与工具 2025年06月12日 16 点赞 0 评论 788 浏览
WaveSpeedAI WaveSpeedAI 是一款集图像与视频生成于一体的 AI 平台,提供多个高性能模型,支持高质量图像生成、个性化风格定制及视频内容创作。平台具备超快速生成能力,适用于创意设计、广告制作和视频内容生产等领域,提供易用接口和企业级部署选项。 AI项目与工具 2025年06月11日 40 点赞 0 评论 768 浏览
Still Still-Moving是一款由DeepMind开发的AI视频生成框架,主要功能包括通过轻量级的空间适配器将用户定制的文本到图像(T2I)模型特征适配至文本到视频(T2V)模型,实现无需特定视频数据即可生成定制视频。其核心优势在于结合T2I模型的个性化和风格化特点与T2V模型的运动特性,从而生成高质量且符合用户需求的视频内容。 AI项目与工具 2025年06月12日 49 点赞 0 评论 752 浏览
VideoDrafter 一个高质量视频生成的开放式扩散模型,相比之前的生成视频模型,VideoDrafter最大的特点是能在主体不变的基础上,一次性生成多个场景的视频。 Ai开源项目 2025年06月05日 89 点赞 0 评论 742 浏览
Genmoai Genmoai-smol 是一款专为单 GPU 设备设计的开源视频生成模型,能够将文本描述转化为高质量视频内容。其核心优势在于高保真度运动表现、强大的文本提示遵循能力及显存优化技术,支持用户在资源受限条件下开展视频创作。该工具提供了 Gradio UI 和命令行界面两种操作方式,并广泛应用于视频内容创作、超现实效果视频制作和技术研究等领域。 AI项目与工具 2025年06月12日 26 点赞 0 评论 733 浏览
Mora Mora是一个多智能体框架,专为视频生成任务设计,通过多个视觉智能体的协作实现高质量视频内容的生成。主要功能包括文本到视频生成、图像到视频生成、视频扩展与编辑、视频到视频编辑以及视频连接。尽管在处理大量物体运动场景时性能稍逊于Sora,Mora仍能在生成高分辨率视频方面表现出色。 AI项目与工具 2024年01月01日 75 点赞 0 评论 730 浏览
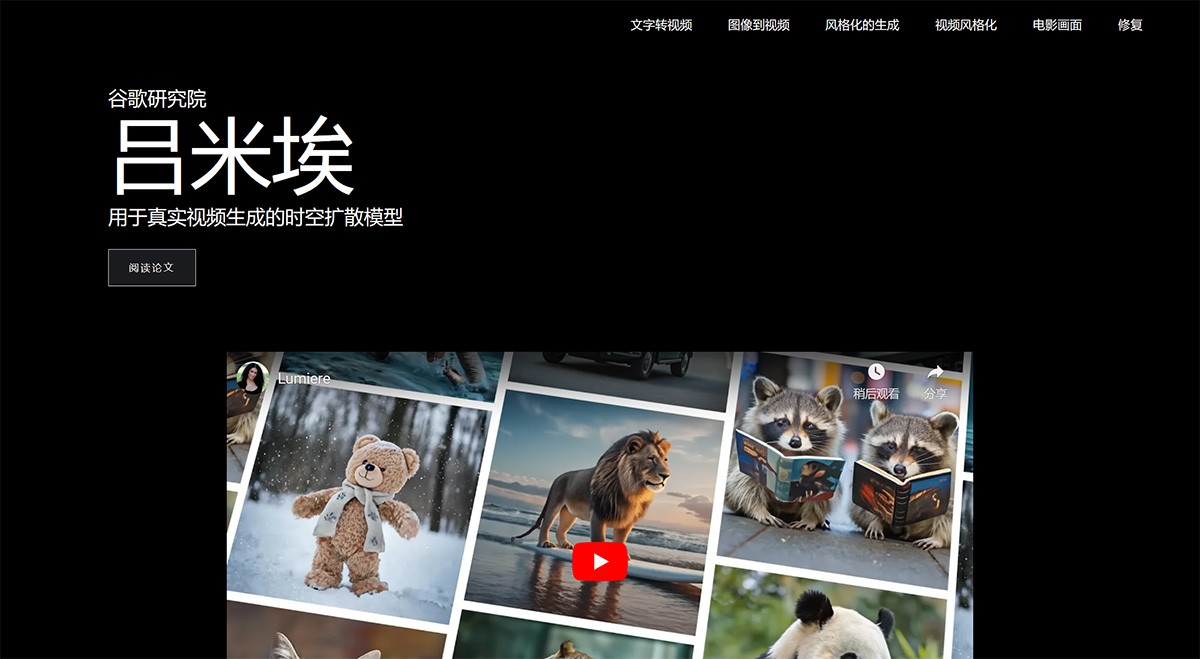
Lumiere 谷歌研究院开发的基于空间时间的文本到视频扩散模型。采用了创新的空间时间U-Net架构,能够一次性生成整个视频的时间长度,确保了生成视频的连贯性和逼真度。 Ai开源项目 2025年06月05日 74 点赞 0 评论 718 浏览
CogVideo 目前最大的通用领域文本生成视频预训练模型,含94亿参数。CogVideo将预训练文本到图像生成模型(CogView2)有效地利用到文本到视频生成模型,并使用了多帧率分层训练策略。 Ai平台模型 2025年06月05日 16 点赞 0 评论 717 浏览