FreeAskInternet FreeAskInternet是一款免费开源的本地AI搜索引擎,集成了先进的大型语言模型和元搜索引擎,支持本地化搜索聚合和智能答案生成。它确保用户数据的私密性和安全性,无需GPU支持即可运行,并提供自定义的大型语言模型选项。此外,FreeAskInternet具备友好的用户界面,可通过简单的部署流程快速搭建。 AI项目与工具 2025年06月12日 76 点赞 0 评论 719 浏览
CrewAI CrewAI是一个开源平台,专注于构建和部署多智能体AI解决方案,支持企业快速自动化关键工作流程。平台具备强大的API集成能力和隐私安全保障,允许用户将多智能体团队转换为API,并在隔离的虚拟私有云环境中运行。CrewAI还提供了丰富的模板和自动化工具,简化智能体的创建和部署过程,并支持多种模型定制选项。此外,CrewAI还拥有高效的监控系统,用于持续改进和优化智能体团队的性能。应用场景涵盖客户服 AI项目与工具 2025年06月12日 75 点赞 0 评论 720 浏览
Pollinations AI Pollinations 是一个通过AI生成媒体内容的平台。平台可能提供多种类型的模板和工具,支持文本、图像、音频、视频等多媒体格式的创作。 3D&游戏 2025年06月05日 62 点赞 0 评论 720 浏览
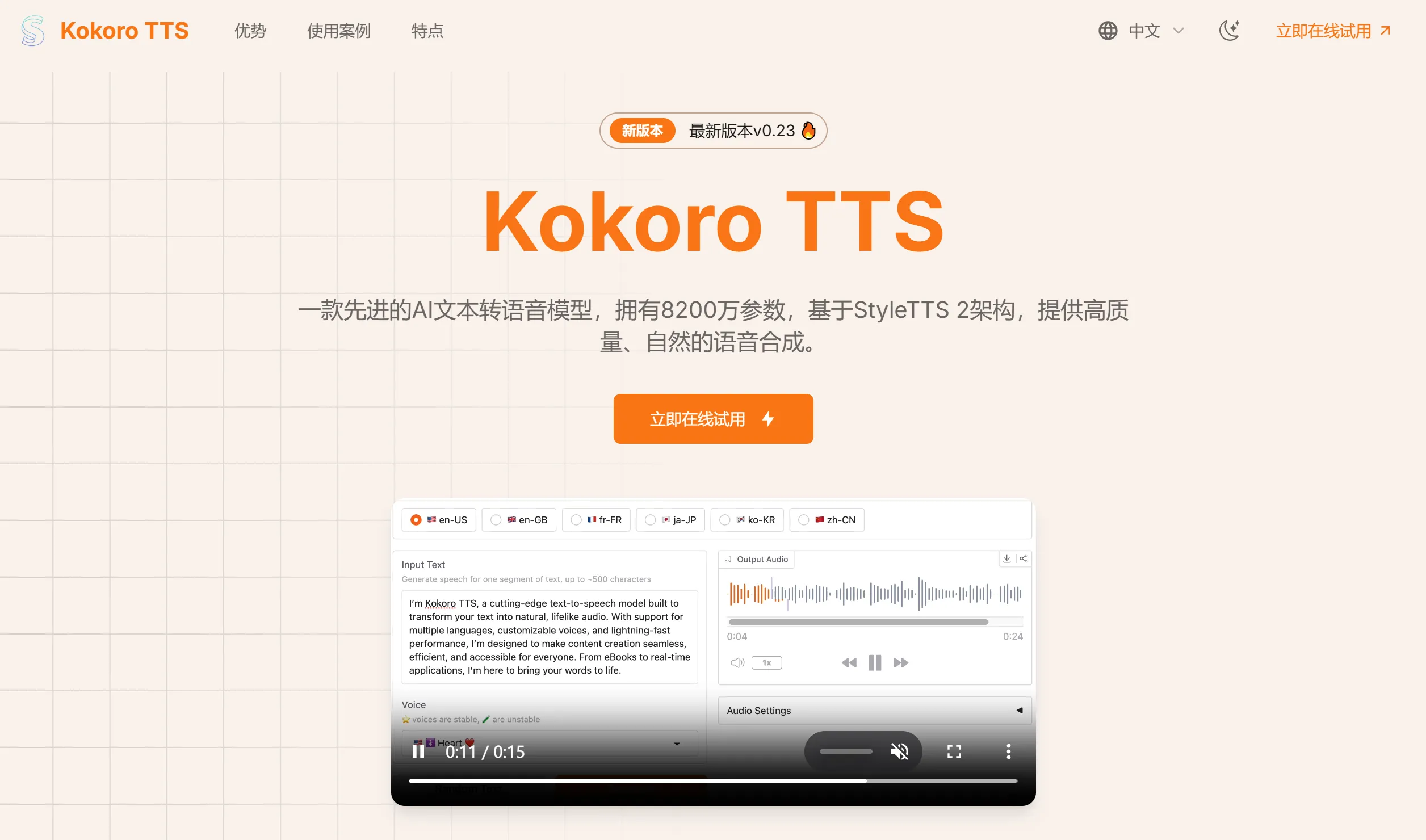
kokoroTTS 一款开源、高性能的文本转语音(TTS)模型,Kokoro TTS拥有8200万参数,基于StyleTTS 2架构,提供高质量、自然的语音合成,适用于有声书、播客等。 Ai语音工具 2025年06月05日 80 点赞 0 评论 721 浏览
Agent Development Kit Agent Development Kit(ADK)是谷歌推出的开源AI智能体开发工具,采用Python实现,支持多智能体架构和复杂任务编排。提供丰富的工具生态、灵活的工作流定义、流式交互支持及广泛的LLM兼容性,帮助开发者快速构建、测试和部署AI代理,提升系统效率与可扩展性。 AI项目与工具 2025年06月11日 47 点赞 0 评论 721 浏览
Chatlog Chatlog 是一款开源聊天记录分析工具,支持微信、QQ、Telegram 等平台的数据解析与可视化。通过智能分析高频词、情感倾向及活跃时段,帮助用户快速提取关键信息。具备本地化处理、数据可视化、自动化报告生成等功能,适用于个人社交分析、团队协作优化及商业客户洞察场景。 AI项目与工具 2025年05月16日 63 点赞 0 评论 721 浏览
FeedMe FeedMe是一款面向Android用户的离线RSS阅读工具,支持多种订阅源,具备内容聚合、自动更新和AI摘要功能。用户可离线阅读文章和播客,提升信息获取效率。基于Web技术构建,支持跨平台使用和个性化部署,适用于日常信息浏览、学习研究、行业跟踪和个人兴趣管理等多种场景。 AI项目与工具 2025年06月11日 23 点赞 0 评论 722 浏览
Kotaemon Kotaemon 是一款基于RAG技术的开源工具,支持用户通过自然语言与文档进行互动,从而实现高效的信息检索和理解。它支持多种语言模型,包括OpenAI、Azure OpenAI和Cohere等,提供简易的安装脚本。Kotaemon 还支持多用户协作、文档管理和复杂的推理方法,并允许用户自定义UI元素。其主要功能包括基于RAG技术的问答系统、多语言模型支持、文档管理、混合RAG管道、多模式问答支持 AI项目与工具 2025年06月12日 30 点赞 0 评论 722 浏览
PySpur PySpur 是一款开源的轻量级可视化 AI 工作流构建工具,支持拖拽式界面,帮助用户快速构建、测试和迭代 AI 应用,无需编写复杂代码。其功能包括循环与记忆、文件处理、结构化输出、RAG 技术、多模态数据支持及与多个平台的集成。适用于智能对话系统、自动化任务管理、多模态数据分析等场景,适合非技术人员和开发者使用。 AI项目与工具 2025年06月12日 28 点赞 0 评论 723 浏览
OOMOL OOMOL(悟墨)是一款基于 VSCode 的现代化 IDE,专为工作流自动化设计。通过拖拽式界面,用户可快速构建复杂流程,无需编程基础。内置 Python 和 Node.js 环境,结合容器化技术实现跨平台一致性和数据安全。原生支持 AI 功能,涵盖数据科学、多媒体处理和模型开发等场景,适合开发者高效构建和共享工作流。 AI项目与工具 2025年06月12日 76 点赞 0 评论 723 浏览