Whisper语音识别模型 Whisper 是一种通用的语音识别模型。它在不同音频的大型数据集上进行训练,也是一个多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。 Ai开源项目 2025年06月05日 90 点赞 0 评论 744 浏览
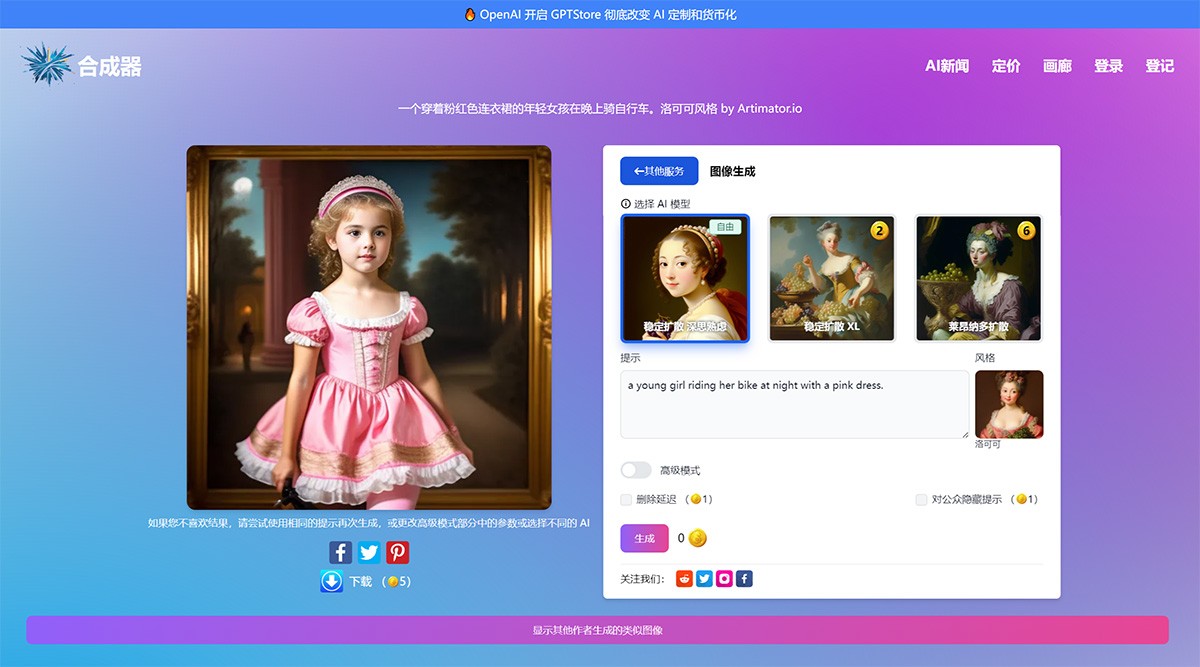
Artimator.Io 一个免费的 AI 驱动的艺术生成器,可让您从文本描述或照片中创建独特的艺术品。它利用 Stable Diffusion 和 SDXL 人工智能,提供了一个多功能平台,用于生成各种风格的艺术作品。 Ai绘画生成 2025年06月05日 61 点赞 0 评论 744 浏览
YuE YuE 是一款由香港科技大学与 Multimodal Art Projection 联合开发的开源 AI 音乐生成模型,支持多语言和多种音乐风格,如流行、金属、爵士、嘻哈等。通过语义增强音频分词器、双分词技术和三阶段训练方案,解决长上下文处理与音乐生成难题,生成结构连贯、旋律优美的歌曲。模型完全开源,用户可自由使用和定制,适用于音乐创作、影视配乐、游戏音效及社交媒体内容制作等多个场景。 AI项目与工具 2025年06月12日 23 点赞 0 评论 745 浏览
FireRedASR FireRedASR是小红书推出的工业级自动语音识别(ASR)模型系列,支持普通话、中文方言和英语,具备高精度和高效推理能力。其包含FireRedASR-LLM和FireRedASR-AED两个版本,分别聚焦于极致精度和计算效率。模型在多个场景如智能助手、视频字幕生成、歌词识别和语音输入中表现出色,且已开源,推动语音识别技术的发展。 AI项目与工具 2025年06月12日 82 点赞 0 评论 745 浏览
Voice Voice-Pro是一款开源的多功能音频处理工具,集成了语音转文字、文本转语音、实时翻译、YouTube视频下载和人声分离等功能,支持超过100种语言,广泛应用于教育、娱乐和商业领域,显著提升音频处理效率和便捷性。 AI项目与工具 2025年06月12日 33 点赞 0 评论 745 浏览
ChatPaper.ai 一个论文、视频、笔记的AI总结学习助手,轻松提炼论文精华、整理课堂重点、生成会议纪要。基于先进AI技术,支持多语言处理,为学生、研究者和职场人士量身打造。 Ai语音工具 2025年06月05日 44 点赞 0 评论 745 浏览
Autoshorts AI 一个将主题和提示转换成简短的垂直视频的全自动视频制作平台。它还支持自动发布到YouTube和 TikTok 并配备可包含音乐的高清输出。 Ai视频生成 2025年06月05日 82 点赞 0 评论 745 浏览
PicHero PicHero是一款基于人工智能技术的修图工具,主要功能包括人脸高清化、日常肖像美化、旧照修复及画质提升。它能够轻松解决低分辨率、模糊或损坏照片的问题,同时支持多语言操作,适用于摄影爱好者、社交媒体用户、专业摄影师以及设计师等不同人群。 AI项目与工具 2025年06月12日 26 点赞 0 评论 746 浏览