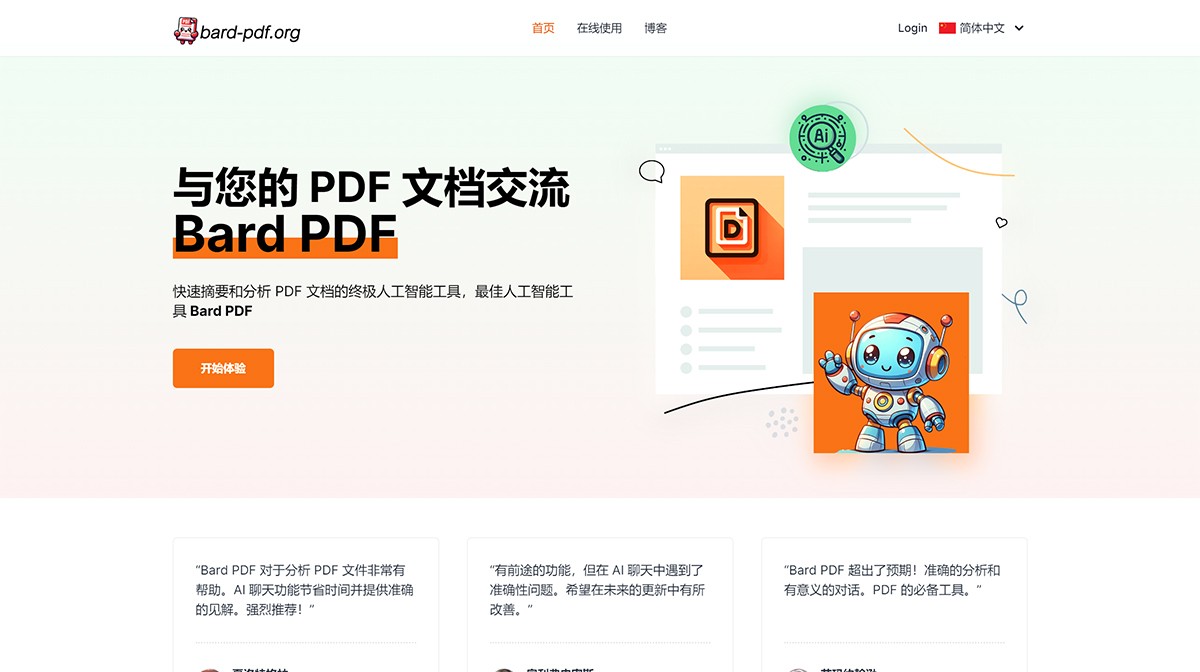
Bard PDF 一个用于汇总和分析 PDF 文档的终极 AI 驱动工具,AI Bard PDF允许用户通过自然对话上传PDF文档并与之交互。 AI写作对话 2025年06月05日 38 点赞 0 评论 532 浏览
Chinese Chinese-LiPS是由智源研究院与南开大学联合开发的高质量中文多模态语音识别数据集,包含100小时语音、视频及手动转录文本。其创新性融合唇读视频与幻灯片内容,显著提升语音识别性能,实验表明可降低字符错误率约35%。适用于教学、科普、虚拟讲解等复杂语境,为多模态语音识别研究提供丰富数据支持。 AI项目与工具 2025年06月11日 47 点赞 0 评论 530 浏览
LaDeCo LaDeCo是一款基于多模态模型的自动化图形设计工具,通过分层规划与逐步生成的方式,实现从多模态输入到高质量设计输出的转换。其核心功能涵盖层规划、层级设计生成、分辨率调整、元素填充及多样化设计输出,广泛适用于设计师、研究人员、评估人员及开发者等群体,助力提升设计效率与质量。 AI项目与工具 2025年06月12日 53 点赞 0 评论 530 浏览
RapiLearn AI RapiLearn AI 是一款基于人工智能的教育工具,支持多种格式学习资料的整合与生成,包括视频、音频、笔记、测试和思维导图等。具备交互式学习功能,提供智能助教服务,可拓展知识点并推荐相关内容。支持多模态学习体验,适用于学生、教师及各类学习者,提升学习效率与知识掌握度。 AI项目与工具 2025年06月12日 99 点赞 0 评论 529 浏览
法唠AI 法唠AI是基于大语言模型开发的法律人工智能工具,专注于证券法与金融法律领域。提供法律问答、知识图谱构建、深度搜索、案件逻辑图绘制、股票信息查询、维权指导及文书生成等功能,支持个性化法律服务,助力用户高效获取法律解决方案。 AI项目与工具 2025年06月12日 87 点赞 0 评论 528 浏览
VideoRAG VideoRAG是一种基于检索增强生成(RAG)技术的工具,旨在提升长视频的理解能力。它通过提取视频中的多模态信息(如OCR、ASR和对象检测),并将其与视频帧和用户查询结合,增强大型视频语言模型的处理效果。该技术轻量高效,易于集成,适用于视频问答、内容分析、教育、媒体创作及企业知识管理等多个领域。 AI项目与工具 2025年06月12日 75 点赞 0 评论 528 浏览
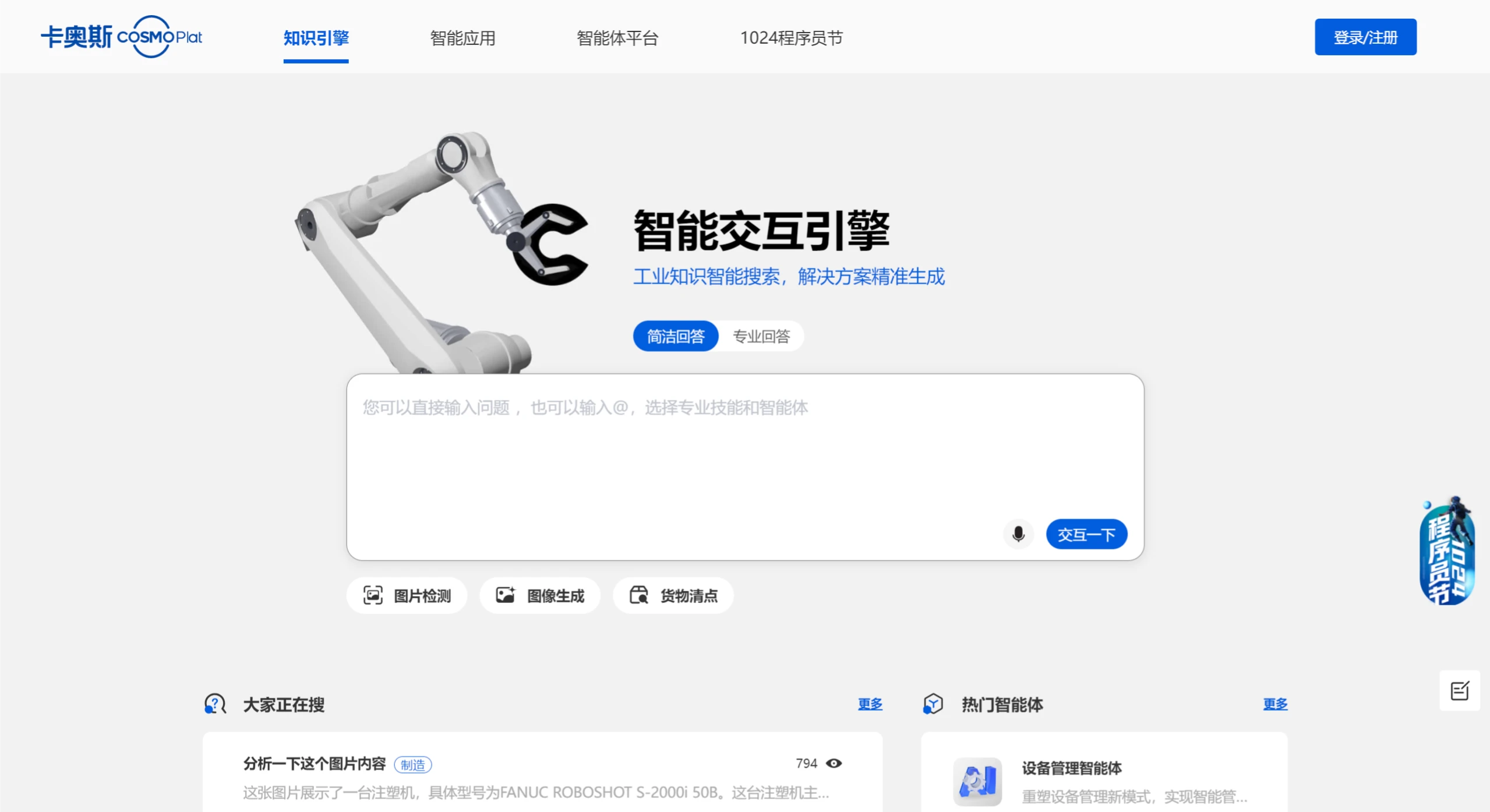
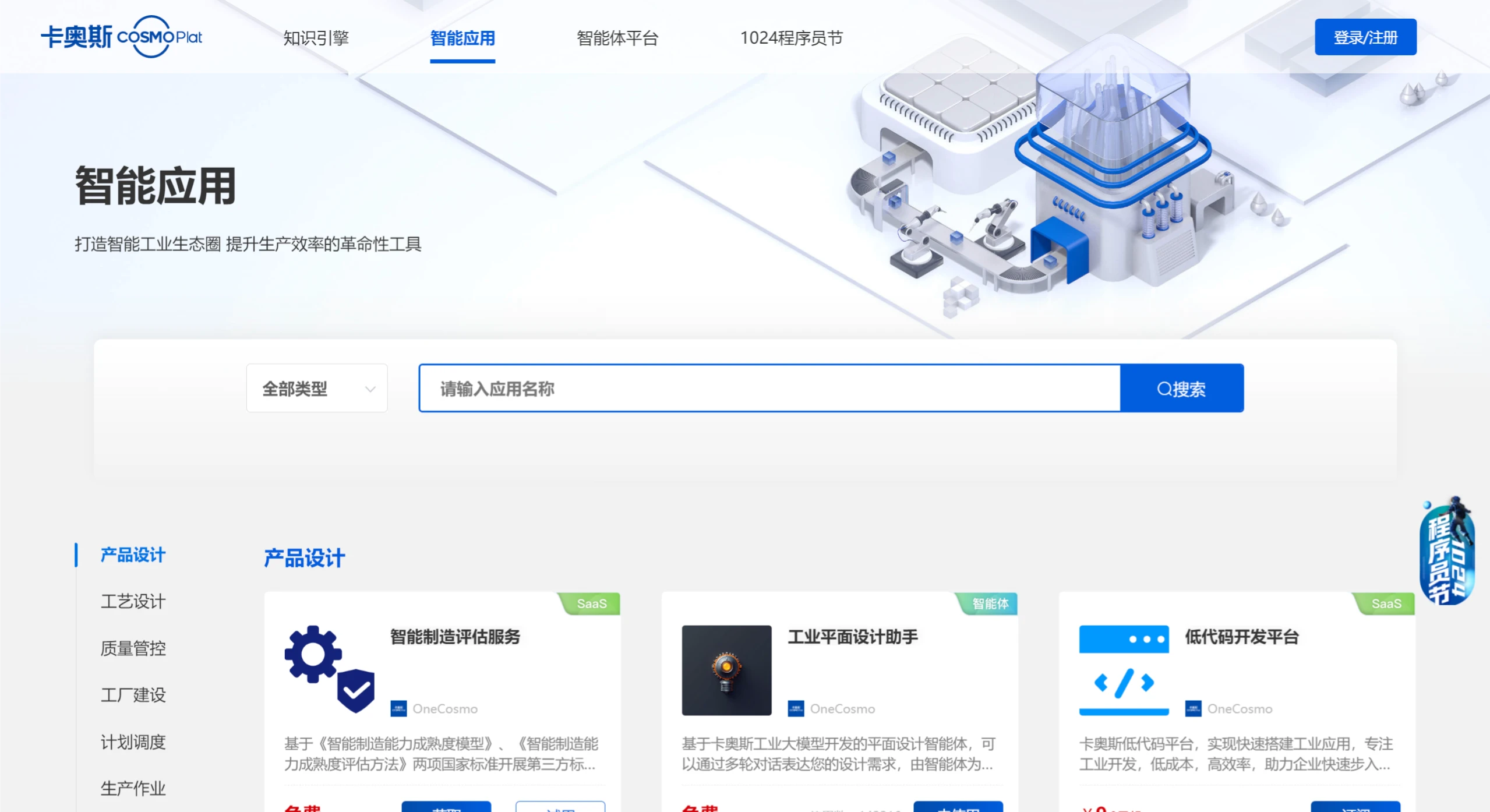
卡奥斯智能交互引擎 一款基于工业大模型技术开发的的工业知识智能搜索和解决方案精准生成平台,融合了智能检索、智能应用和多模态连续交互等多种功能。 AI搜索问答 2025年06月05日 86 点赞 0 评论 528 浏览
讯飞星火X1 讯飞星火X1是科大讯飞推出的基于全国产算力平台训练的大型语言模型,具备深度推理和“慢思考”能力,适用于数学、代码、逻辑推理、文本生成等任务。支持快慢思考统一模型,部署简便,算力需求低。广泛应用于教育、医疗、健康管理等领域,提供精准的智能服务与解决方案。 AI项目与工具 2025年06月12日 99 点赞 0 评论 527 浏览
Ming Ming-Lite-Omni是蚂蚁集团开源的统一多模态大模型,基于MoE架构,支持文本、图像、音频和视频等多种模态的输入输出,具备强大的理解和生成能力。模型在多个任务中表现优异,如图像识别、视频理解、语音问答等,适用于OCR识别、知识问答、视频分析等多个领域。其高效处理能力和多模态交互特性,为用户提供一体化智能体验。 AI项目与工具 2025年06月11日 79 点赞 0 评论 527 浏览