AtomoVideo AtomoVideo是一款高保真图像到视频生成框架,能够从静态图像生成高质量视频内容。它通过多粒度图像注入和高质量数据集及训练策略,保证生成视频与原始图像的高度一致性和良好的时间连贯性。此外,AtomoVideo还支持长视频生成、文本到视频生成以及个性化和可控生成等功能。 AI项目与工具 2024年01月01日 32 点赞 0 评论 550 浏览
BasedLabs BasedLabs是一款基于AI技术的图像和视频创作平台,提供包括AI视频生成、图像创作、图像扩展及换脸在内的多种功能。用户可利用平台内置的AI模型生成高质量的视觉内容,适用于社交媒体、数字艺术、广告营销、影视制作、游戏开发以及教育培训等多个领域。平台操作简便,适合各类创作者使用。 AI项目与工具 2025年06月12日 12 点赞 0 评论 548 浏览
OCRmyPDF OCRmyPDF 是一款开源的命令行工具,用于将扫描 PDF 转换为可搜索、可编辑的文档。基于 Tesseract OCR 引擎,支持 100 多种语言,具备图像优化、纠偏、清洁等功能,提升识别准确率。支持多核处理与批量操作,适合高效处理大量文件,且完全离线运行,保障数据安全。 AI项目与工具 2025年06月12日 39 点赞 0 评论 548 浏览
xAR xAR是由字节跳动与约翰·霍普金斯大学联合研发的自回归视觉生成框架,采用“下一个X预测”和“噪声上下文学习”技术,提升视觉生成的准确性和效率。其支持多种预测单元,具备高性能生成能力,在ImageNet数据集上表现优异,适用于艺术创作、虚拟场景生成、老照片修复、视频内容生成及数据增强等多种应用场景。 AI项目与工具 2025年06月12日 30 点赞 0 评论 548 浏览
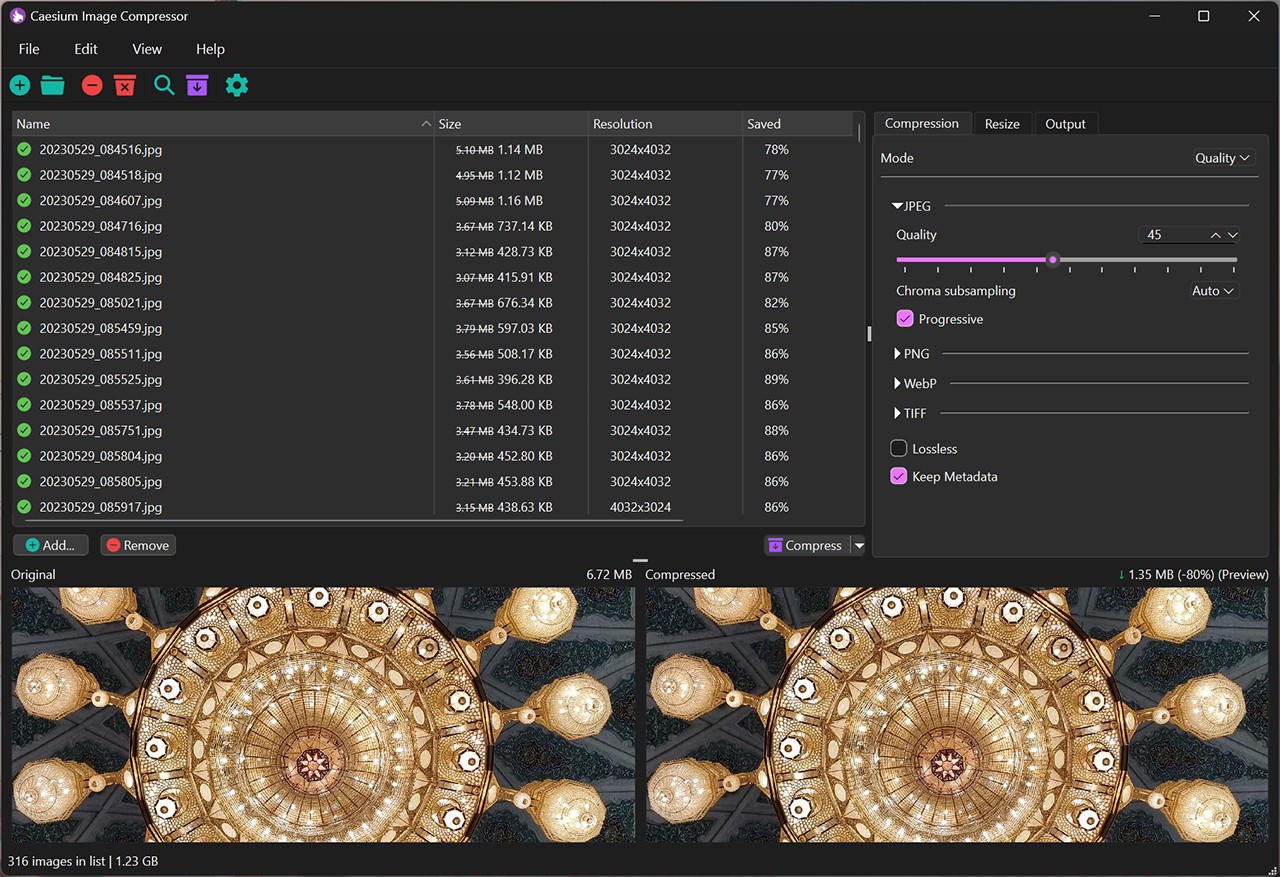
Caesium.app 一款免费的开源在线图像压缩工具,Caesium支持JPG、PNG等格式的批量处理和预览功能。能将照片压缩至原始大小的90%。 图片处理 2025年06月05日 60 点赞 0 评论 547 浏览
M2UGen M2UGen是由腾讯PCG ARC实验室与新加坡国立大学共同研发的一款多模态音乐理解和生成框架,支持从文本、图像、视频等多种模态输入生成相应音乐。它具有强大的音乐理解能力、灵活的音乐编辑功能以及多样化的应用场景,适用于音乐制作、影视配乐、音乐教育等多个领域。凭借其创新的技术架构和卓越的表现力,M2UGen已成为当前最优秀的多模态音乐生成工具之一。 AI项目与工具 2025年06月12日 51 点赞 0 评论 547 浏览
LLMDet LLMDet是一款基于大型语言模型协同训练的开放词汇目标检测器,能够识别训练阶段未见过的目标类别。其通过结合图像和文本信息,实现高精度的零样本检测,并支持图像描述生成与多模态任务优化,适用于多种实际应用场景。 AI项目与工具 2025年06月12日 68 点赞 0 评论 547 浏览
ChatPlayground AI ChatPlayground AI 是一个集成了多种行业领先AI模型的多AI聊天机器人平台。用户可以在一个统一的界面中与多个AI进行互动,获得更全面的答案。该平台支持多语言交流,并具备多重AI视角、行业领先的AI模型、提示库、实时网页搜索以及图像生成等功能。ChatPlayground AI适用于学术研究、内容创作、日常咨询等多个场景,为用户提供强大的辅助功能,帮助用户节省时间和提高效率。 AI项目与工具 2025年06月12日 55 点赞 0 评论 547 浏览
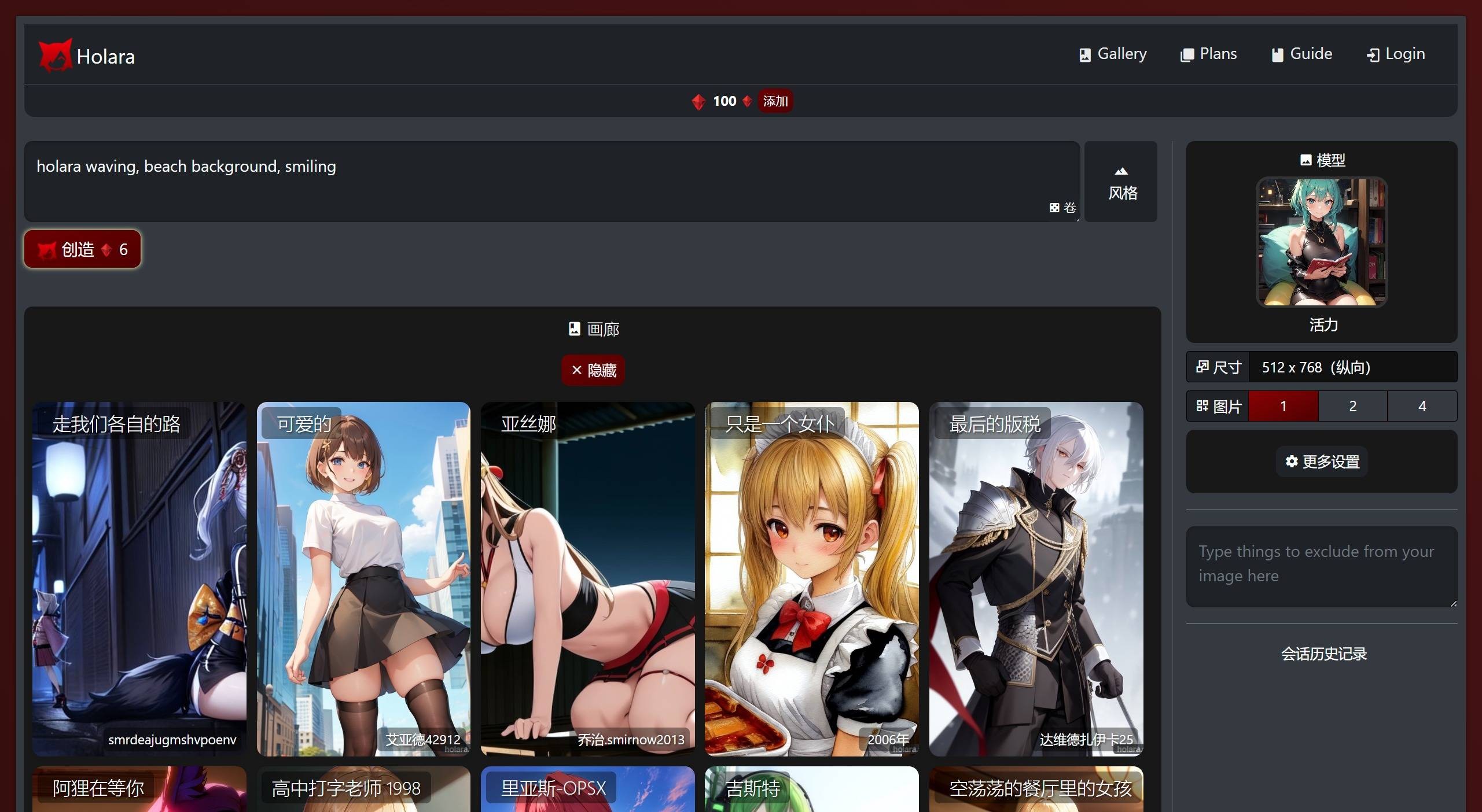
Holara AI 一款AI动漫画卡通图片生成工具,用户只需输入他们的偏好和提示,然后Holara AI就会生成符合给定条件的动漫图像。 Ai绘画生成 2025年06月05日 17 点赞 0 评论 545 浏览