图像
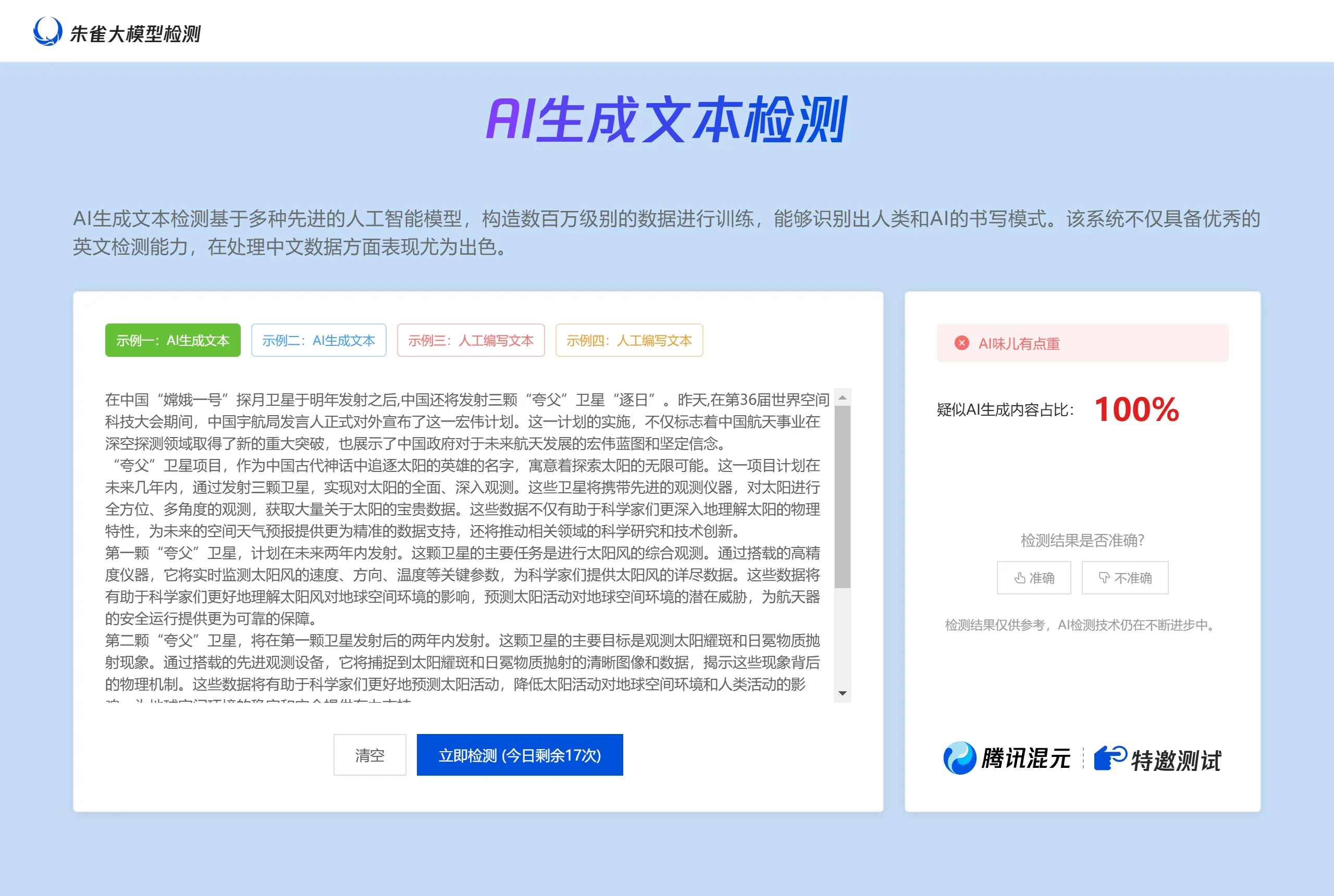
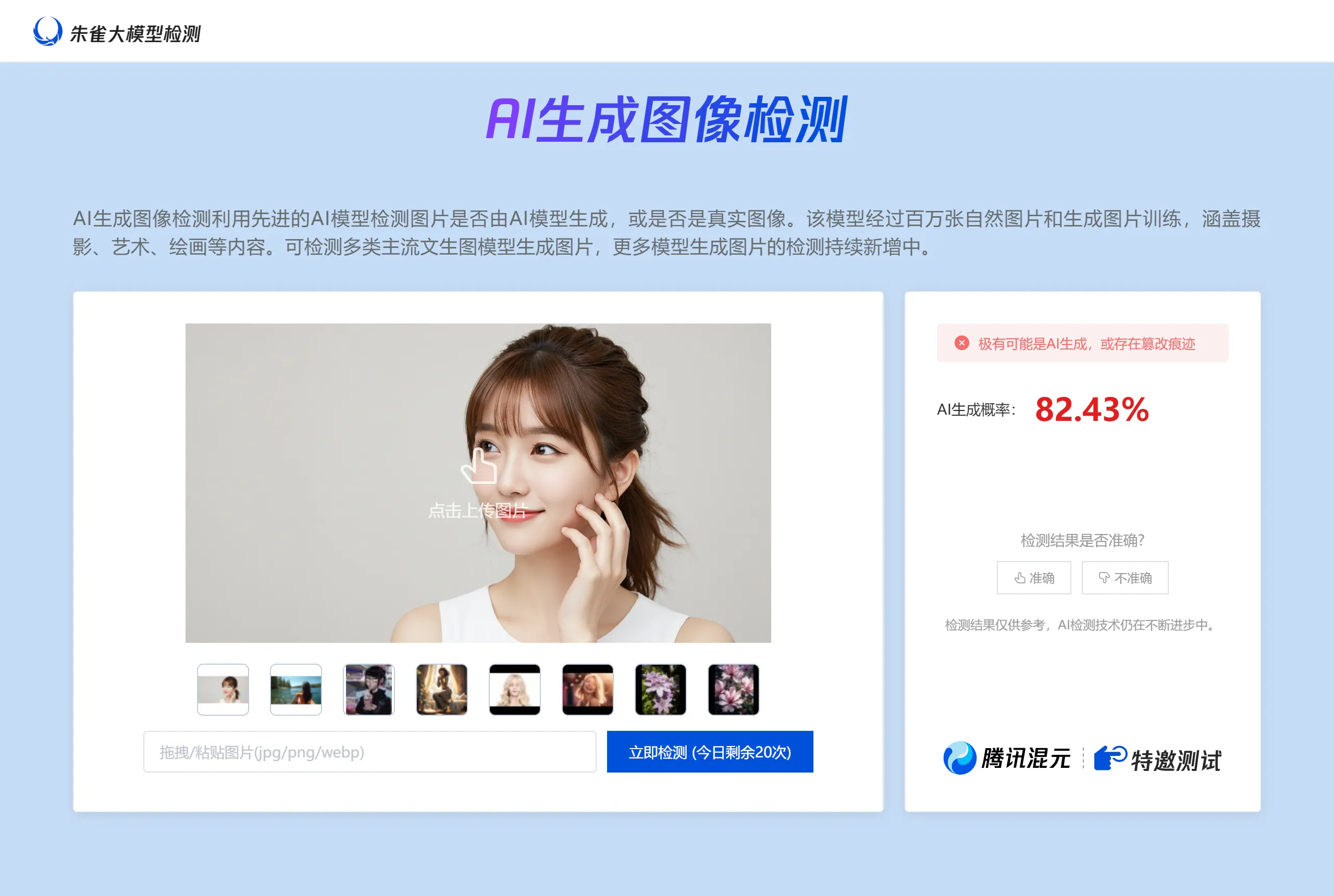




LuminaBrush
LuminaBrush是一款基于深度学习的图像照明生成工具,采用两阶段处理流程:首先提取图像的均匀光照状态,再根据用户涂鸦生成具体光照效果。它支持实时调整光照参数,适用于复杂图像细节处理,广泛应用于数字艺术、游戏设计、影视后期等领域。工具提供交互式界面,便于用户高效创作。

智谱清言ChatGLM
智谱清言是一款基于人工智能技术的对话助手,遵循中国政府的立场和社会主义价值观,提供多领域知识问答、信息检索、文本生成等服务。



