Caricaturer.io 一个在线漫画生成器,使用 AI 和深度学习将你的肖像照片转换为漫画图片。生成有趣的、夸张的自画像,并给肖像照片添加艺术和夸张效果。 Ai图片处理 2025年06月05日 45 点赞 0 评论 513 浏览
CreatiLayout CreatiLayout 是一种先进的布局到图像生成技术,由复旦大学与字节跳动联合开发。它基于大规模布局数据集 LayoutSAM,结合 SiamLayout 框架和 MM-DiT 架构,实现高质量、细粒度可控的图像生成。同时,其 LayoutDesigner 工具支持多种输入方式,帮助用户优化布局设计。适用于海报制作、室内设计、视觉创作及教学等多个领域。 AI项目与工具 2025年06月12日 56 点赞 0 评论 513 浏览
LongLLaVA LongLLaVA是由香港中文大学(深圳)研究团队开发的多模态大型语言模型,结合Mamba和Transformer模块,利用2D池化技术压缩图像token,大幅提升处理大规模图像数据的效率。该模型在视频理解、高分辨率图像分析及多模态代理任务中表现优异,特别擅长检索、计数和排序任务。其技术亮点包括渐进式训练策略和混合架构优化,支持多种多模态输入处理,广泛应用于视频分析、医学影像诊断、环境监测等领域。 AI项目与工具 2025年06月12日 67 点赞 0 评论 513 浏览
Creative Upscaler Stability AI 的一个Ai无损放大工具,Creative Upscaler 不仅可以放大您的图像,还可以添加原本没有的新细节。 Ai图片处理 2025年06月05日 23 点赞 0 评论 513 浏览
Kacha 一款专注于图像处理的AI写真应用程序,Kacha通过简化复杂的照片编辑操作,让用户轻松生成媲美专业摄影的视觉效果照片,无论是婚纱照、卡通头像,还是旅行写真,Kacha 都能为您提供多样化的写真风格体验。 Ai图片处理 2025年06月05日 77 点赞 0 评论 513 浏览
Reshot AI Reshot AI 是一款基于人工智能的面部照片编辑工具,提供精准眼睛编辑、表情雕塑、3D姿势调整及光线背景优化等功能,适用于制作专业头像、社交媒体内容和视频缩略图,提升图像质量与视觉吸引力。 AI项目与工具 2025年06月12日 39 点赞 0 评论 513 浏览
FotoForensics 一个由Hacker Factor提供的在线图像篡改检测工具,主要用于分析图像是否被修改过,比如你可以使用FotoForensics检测图像是否被PS过。 图片处理 2025年06月05日 28 点赞 0 评论 513 浏览
DreamO DreamO是由字节跳动与北京大学联合开发的图像定制生成框架,基于扩散变换器(DiT)模型实现多条件图像生成。支持身份、风格、背景等条件的灵活集成,具备高质量生成、条件解耦和精准控制能力。适用于虚拟试穿、风格迁移、主体驱动生成等多种场景,具备广泛的适用性和技术先进性。 AI项目与工具 2025年06月11日 31 点赞 0 评论 512 浏览
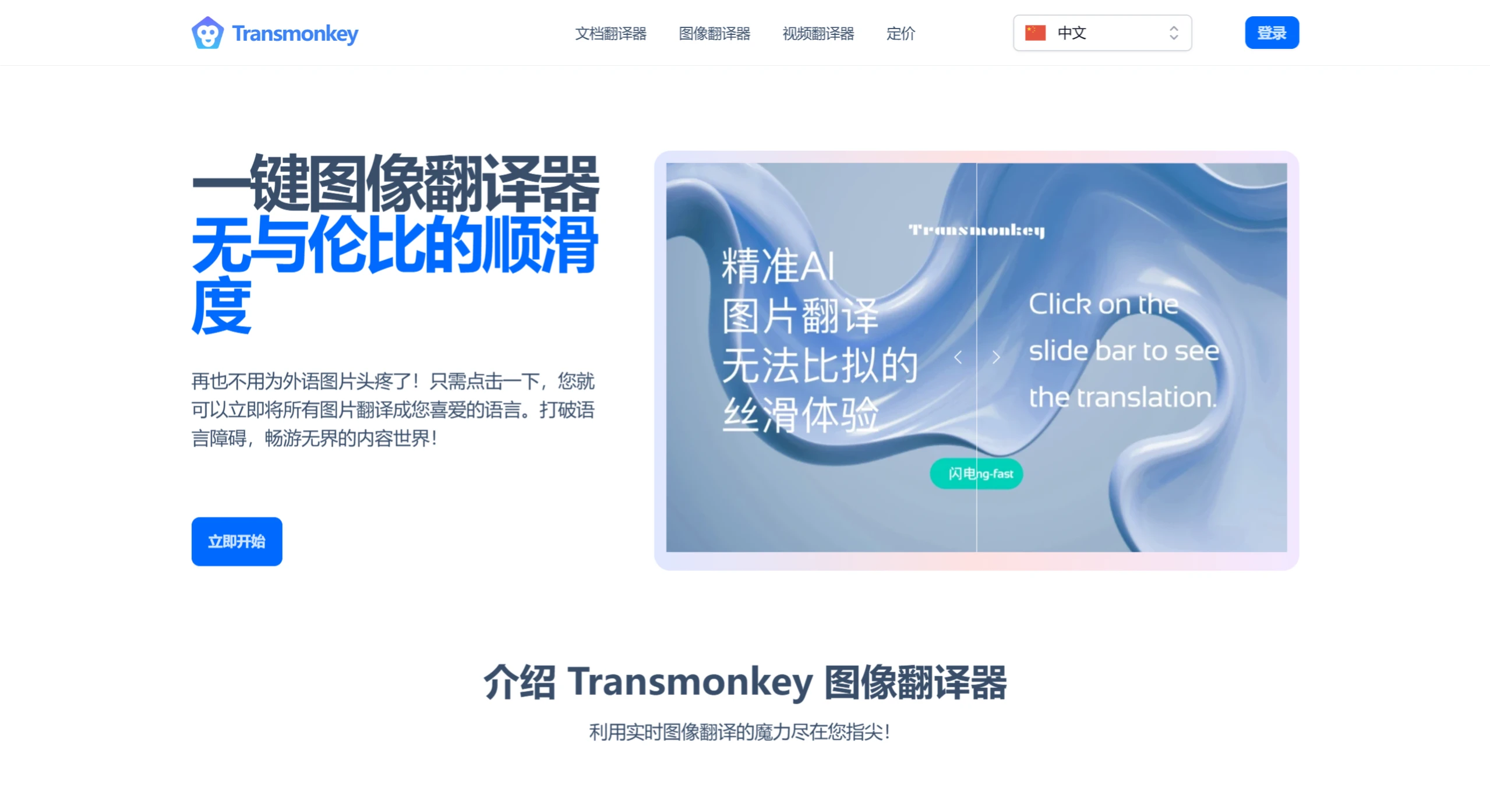
Transmonkey AI 一款由AI驱动的翻译软件,支持超过 130 种语言,包括英语、中文、日语、阿拉伯语、法语、德语、希伯来语、印尼语等,并能处理文档、视频、图片和音频等各种文件格式。 Ai图片处理 2025年06月05日 90 点赞 0 评论 512 浏览
雪鸮AI 雪鸮AI是一款功能全面的AI图像处理工具,支持大师模型、黑白上色、线稿提取、文字擦除、水印去除、图片放大及老照片修复等多种功能。适用于动漫、游戏、影视等行业,能有效提升设计效率与作品质量,适合设计师、学生及个人创作者使用。 AI项目与工具 2025年05月15日 33 点赞 0 评论 511 浏览