Remaker Remaker是一个在线AI工具,专注于创意内容的生成。它利用生成式AI技术,为用户提供了多种功能,包括AI换脸、批量换脸、多人换脸、视频换脸等,满足不同场景下的内容创作需求。 Ai视频生成 2026年06月24日 0 点赞 0 评论 722 浏览
Shot Rate Shot Rate是一种用于电商的 AI 工具,可以生成无限变化的产品图像。它使用基于用户原始图像训练的自定义 AI 模型,为营销和宣传材料创建独特且高质量的产品视觉效果。 Ai绘画生成 2025年06月05日 41 点赞 0 评论 723 浏览
Reve Image Reve Image 是一款基于 AI 的图像生成工具,具备强大的视觉表现力与精准的提示理解能力。支持文生图和图生图模式,适用于广告设计、社交媒体内容创作、艺术创作及产品设计等多种场景。模型在色彩、光影和排版上优化显著,可生成高质量且富有设计感的图像。 AI项目与工具 2025年06月12日 44 点赞 0 评论 723 浏览
千鹿AI 一款轻量级、功能丰富的AI工具合集。通过接入AI功能,千鹿AI可以和多个设计软件联动,能够快速生成用户需要的图像内容,节省用户手动设计、编辑图像和处理日常任务的时间,从而提高工作效率。 Ai图片处理 2025年06月05日 93 点赞 0 评论 723 浏览
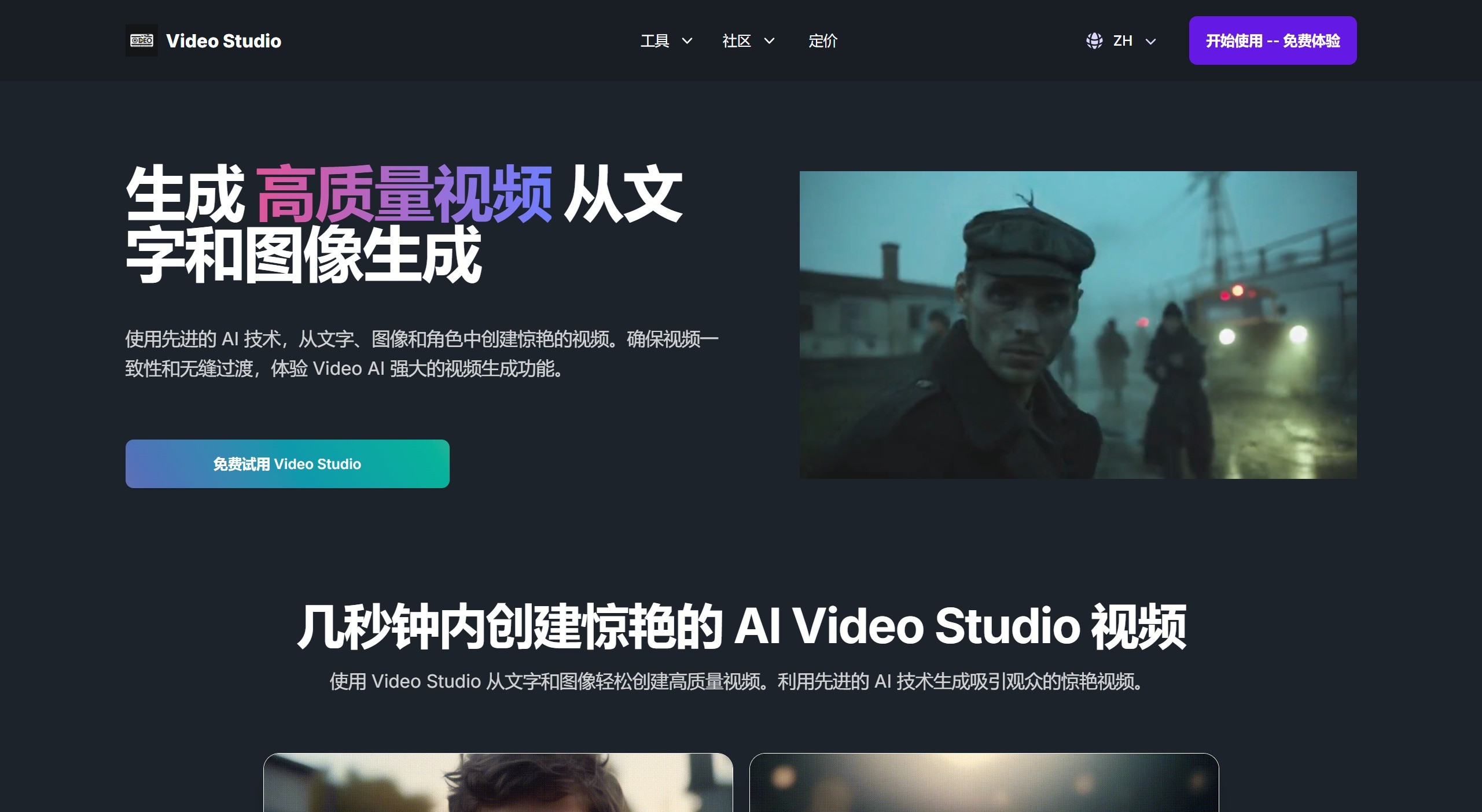
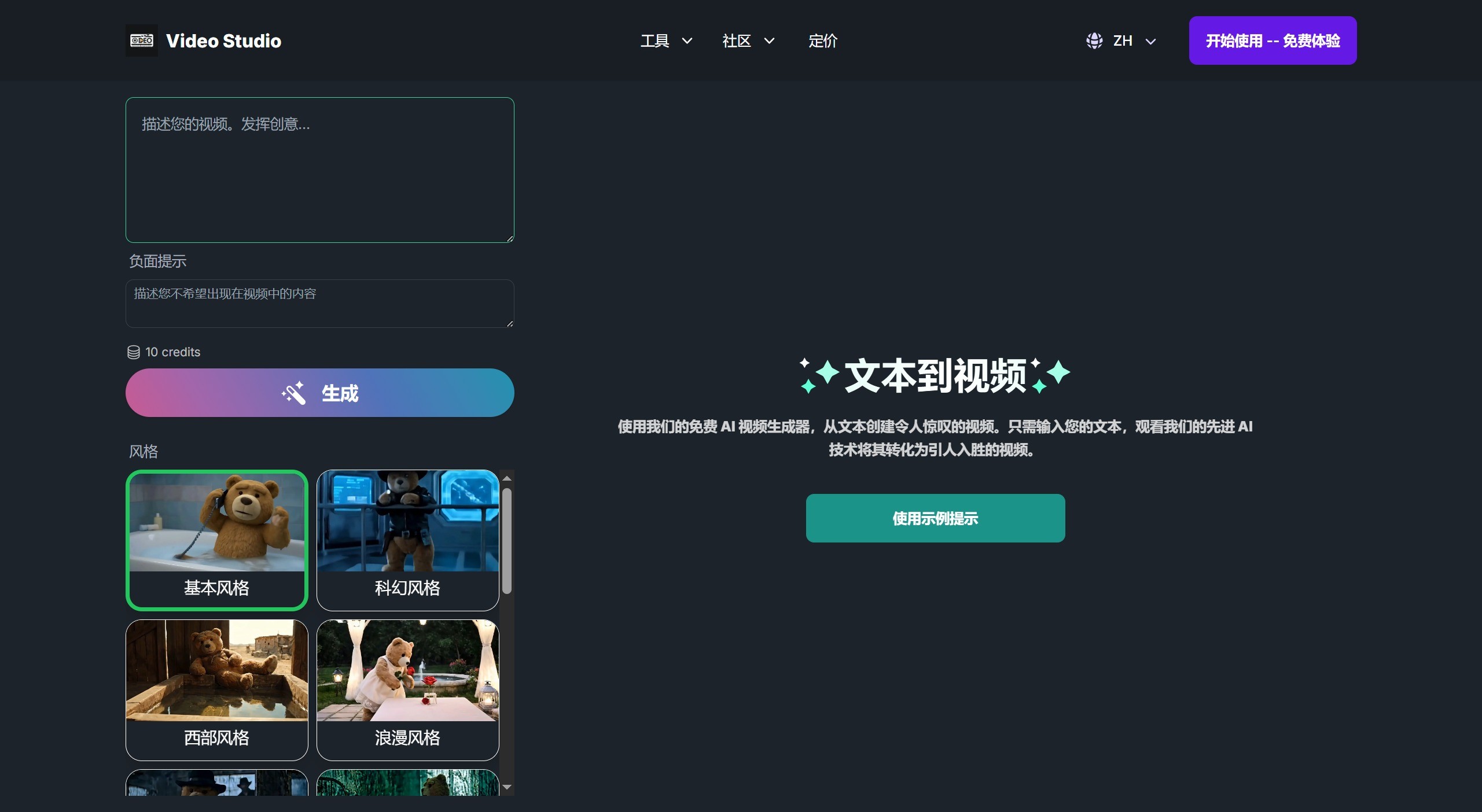
Video Studio 一款利用先进AI技术将文本和图像转换为视频的工具,用户可以通过简单的操作,将文字或图片上传至平台,AI会自动生成高质量的视频。 Ai视频生成 2025年06月05日 12 点赞 0 评论 723 浏览
FutureKid FutureKid是一款基于AI技术预测孩子未来长相的应用,通过分析父母面部特征生成逼真图像。它支持个性化定制,注重隐私保护,确保数据安全。适用于家庭规划、婚礼纪念及创意设计等多种场景,提供简单高效的用户体验。 AI项目与工具 2025年06月12日 14 点赞 0 评论 723 浏览
Myimg AI Myimg AI是一款基于先进AI技术的卡通化工具,可将用户上传的照片快速转化为海贼王风格的卡通画像。它提供多种风格选择与个性化定制选项,简化了图像处理流程,适用于社交媒体、艺术创作、营销推广及个性化礼品制作等多个领域。此外,该工具注重数据安全与隐私保护,确保用户信息安全。 AI项目与工具 2025年06月12日 56 点赞 0 评论 724 浏览
Cleanpng | KissPNG CleanPNG(KissPNG)一个可以免费下载PNG免抠素材的网站,所有透明图像都可以免费下载,并且无限制。 免商图片 2025年06月05日 89 点赞 0 评论 724 浏览
讯飞星火PC版 讯飞星火PC版是科大讯飞推出的一款桌面级AI工具,集成了强大的跨领域知识理解和语言处理能力。它支持自然对话方式,涵盖写作、搜索、问答、翻译、PPT生成、图像生成等功能,并新增了深度搜索与多模态交互能力,可广泛应用于办公、教育、内容创作和技术开发等领域,提供高效便捷的智能服务。 AI项目与工具 2024年10月29日 65 点赞 0 评论 726 浏览