VideoAnydoor VideoAnydoor是一款由多所高校与研究机构联合开发的视频对象插入系统,基于文本到视频的扩散模型,支持高保真对象插入与精确运动控制。其核心模块包括ID提取器和像素变形器,能实现对象的自然融合与细节保留。该工具适用于影视特效、虚拟试穿、虚拟旅游、教育等多个领域,具备良好的通用性和扩展性。 AI项目与工具 2025年06月12日 61 点赞 0 评论 719 浏览
SwiftEdit SwiftEdit是一款基于文本引导的图像编辑框架,利用一步反演技术和掩码引导编辑技术,可在极短时间内实现高质量图像编辑,同时保持背景元素完整。它支持快速文本引导编辑、一步反演框架及自引导编辑掩码提取,并具备灵活的注意力重缩放机制,广泛应用于社交媒体、广告营销、新闻媒体、艺术创作和电子商务等领域。 AI项目与工具 2025年06月12日 53 点赞 0 评论 720 浏览
MIDI MIDI是一种基于多实例扩散模型的3D场景生成技术,能将单张2D图像快速转化为高保真度的360度3D场景。它通过智能分割、多实例同步扩散和注意力机制,实现高效的3D建模与细节优化。具有良好的泛化能力,适用于游戏开发、虚拟现实、室内设计及文物数字化等多个领域。 AI项目与工具 2025年06月12日 64 点赞 0 评论 721 浏览
啵啵动漫 啵啵动漫是一款基于AI技术的视频处理工具,支持将普通视频一键转换为多种动漫风格,提供丰富的模板和自定义选项。平台涵盖AI写真、AI魔法脸、AI文生图等功能,支持音乐、特效添加,适用于个人创作、二次元文化体验及创意视频制作。用户还可浏览社区内容并进行互动,提升创作体验。 AI项目与工具 2025年06月12日 56 点赞 0 评论 721 浏览
MarDini MarDini是一款融合掩码自回归(MAR)和扩散模型(DM)的先进视频生成工具,支持视频插值、图像到视频生成、视频扩展等多种任务。它通过优化计算资源分配,提高了视频生成的效率与灵活性,并具备从无标签数据中进行端到端训练的能力,展现出强大的可扩展性与效率。 AI项目与工具 2025年06月12日 44 点赞 0 评论 721 浏览
DiffusionGPT DiffusionGPT是一款基于大型语言模型的开源文本到图像生成系统,由字节跳动与中山大学联合开发。它采用思维树和优势数据库技术,能够解析和处理多样化的文本提示,生成高质量图像。系统通过多模型的选择与集成、基于人类反馈的优化以及高效的图像生成执行,实现了从文本到图像的无缝转换。DiffusionGPT适用于多种应用场景,具有广泛适用性和灵活性。 AI项目与工具 2024年01月01日 93 点赞 0 评论 721 浏览
Diffuse to Choose 一种基于扩散的图像修复模型,主要用于虚拟试穿场景。它能够在修复图像时保留参考物品的细节,适用于在线购物等虚拟试穿场景中的图像修复任务。 Ai开源项目 2025年06月05日 74 点赞 0 评论 722 浏览
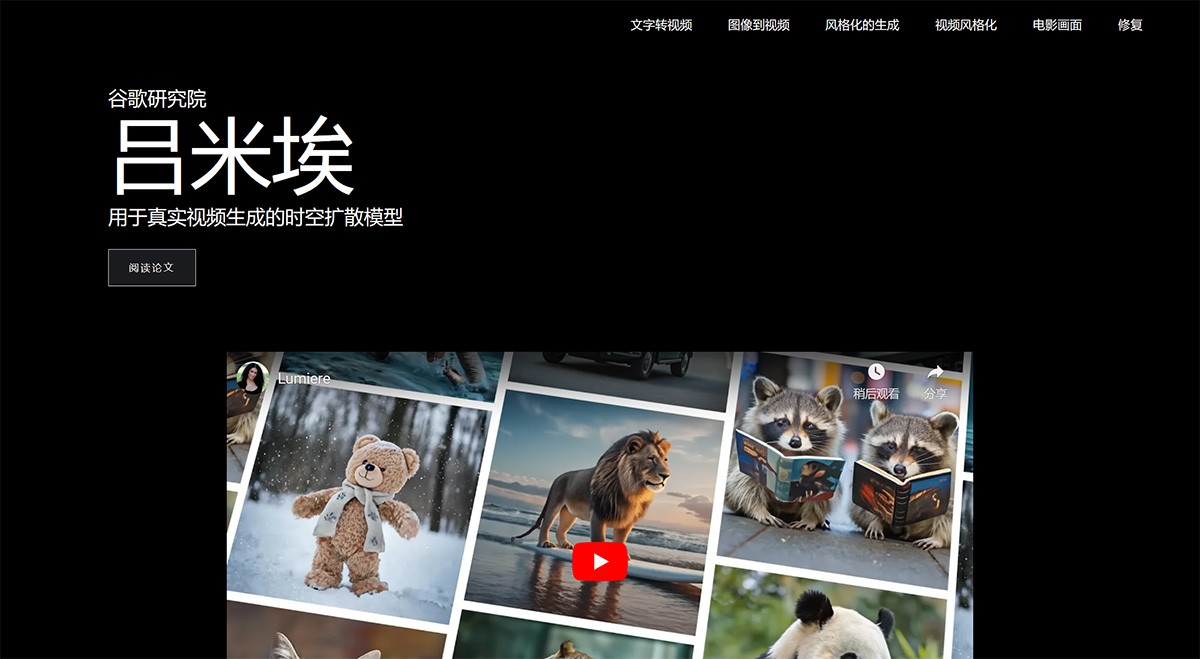
Lumiere 谷歌研究院开发的基于空间时间的文本到视频扩散模型。采用了创新的空间时间U-Net架构,能够一次性生成整个视频的时间长度,确保了生成视频的连贯性和逼真度。 Ai开源项目 2025年06月05日 74 点赞 0 评论 722 浏览
WarpVideo WarpVideo是一款基于人工智能的视频创作工具,提供视频转视频、图像转视频、文本转视频及视频缩放等多种功能,支持用户快速高效地完成视频风格转换与格式调整。它广泛应用于电影制作、营销推广、社交媒体内容创作、教育培训及新闻报道等领域,助力用户轻松打造专业级视频内容。 AI项目与工具 2025年06月12日 42 点赞 0 评论 722 浏览