Dreamlike.Art Dreamlike.Art是一个免费的人工智能艺术生成器和创作工具,利用人工智能的力量,用户可以在几秒钟内创建令人惊叹的原创艺术。它提供图像升级、创建变化、修复面部等功能。 Ai绘画生成 2025年06月05日 22 点赞 0 评论 604 浏览
Jina AI 一家一家专注于神经搜索技术的商业开源软件公司,Jina AI致力于通过深度学习技术简化非结构化数据的搜索,提供高效、准确的搜索解决方案。 AI搜索问答 2025年06月05日 80 点赞 0 评论 604 浏览
书生·筑梦2.0(Vchitect 2.0) 书生·筑梦2.0是一款由上海人工智能实验室开发的开源视频生成大模型,支持文本到视频和图像到视频的转换,生成高质量的2K分辨率视频内容。它具备灵活的宽高比选择、强大的超分辨率处理能力以及创新的视频评测框架,适用于广告、教育、影视等多个领域。 AI项目与工具 2025年06月12日 32 点赞 0 评论 605 浏览
Oryx Oryx是一款由清华大学、腾讯和南洋理工大学联合开发的多模态大型语言模型,专为处理视觉数据设计。其核心技术包括预训练的OryxViT模型和动态压缩模块,支持任意分辨率的图像处理及高效的视觉数据压缩。Oryx在空间和时间理解上表现优异,广泛应用于智能监控、自动驾驶、人机交互、内容审核、视频编辑及教育等领域。 AI项目与工具 2025年06月12日 100 点赞 0 评论 605 浏览
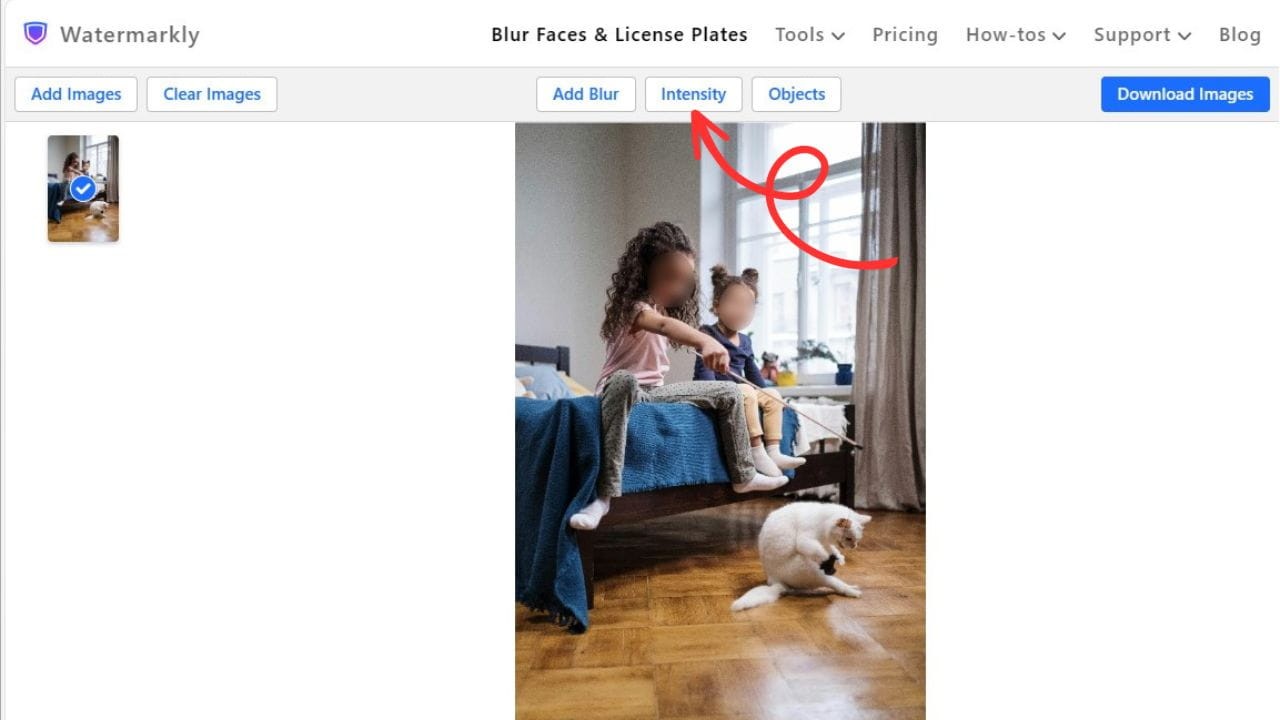
Watermarkly 一款用于自动模糊照片部分的惊人应用程序,有了Watermarkly,您将能够在一批照片中模糊人脸和车牌,并在几分钟内保护您的敏感信息。 Ai图片处理 2025年06月05日 66 点赞 0 评论 605 浏览
Eden AI Eden AI 是一个简化产品,测试和集成不同的 AI 解决方案,而无需处理多个帐户、计费系统或技术复杂性的平台。 Ai学习资源 2025年06月05日 54 点赞 0 评论 605 浏览
Blend Blend Now 是一个提供在线图像背景移除服务的网站。该网站利用AI技术,可以快速、准确地移除照片的背景,或者更改照片的背景颜色。 电商运营 2025年06月05日 90 点赞 0 评论 606 浏览
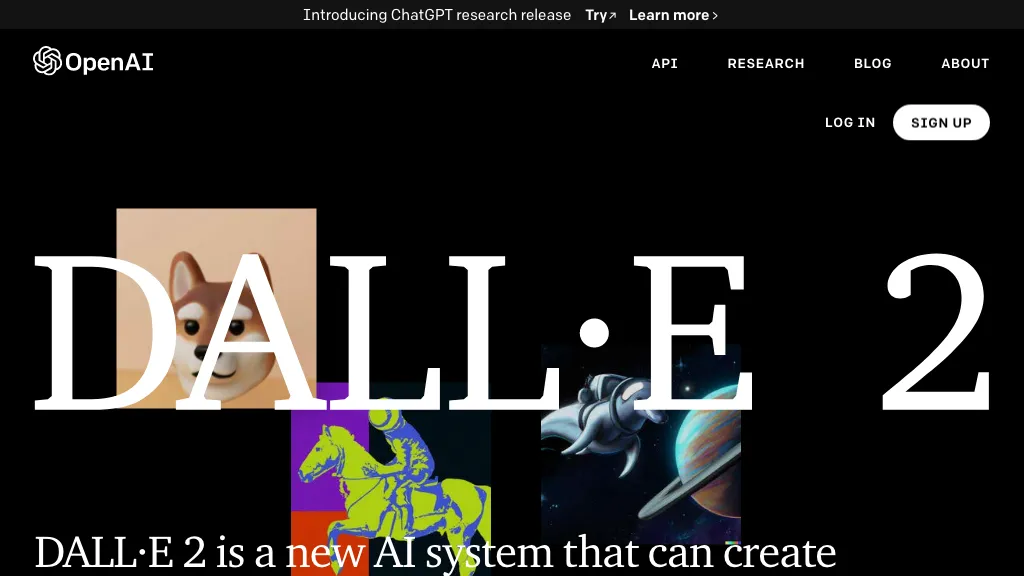
DALL OpenAI 的人工智能图像生成器,允许用户根据文本描述轻松生成高度准确的图像。DALL·E 3 理解细微差别和细节,从而生成完全符合所提供文本的图像。 Ai平台模型 2025年06月05日 56 点赞 0 评论 606 浏览
ShipAny ShipAny 是一款基于 NextJS 的 AI SaaS 开发工具,提供丰富模板、基础设施集成和一键部署功能,助力开发者快速构建 AI 相关产品。支持身份验证、支付处理、AI 图像生成、SDK 集成及 SEO 优化,适用于全球市场。涵盖写作助手、智能问答、图像生成等多种应用场景,适合初创企业与开发者使用。 AI项目与工具 2025年06月12日 63 点赞 0 评论 607 浏览
RegionDrag RegionDrag是一种基于区域的图像编辑技术,由香港大学和牛津大学联合开发。该技术利用扩散模型,让用户通过定义手柄区域和目标区域来实现快速且精确的图像编辑。RegionDrag在单次迭代中完成编辑任务,显著减少编辑时间,同时采用注意力交换技术增强编辑的稳定性和自然性。主要应用领域包括数字艺术与设计、照片编辑、虚拟现实、游戏开发以及电影和视频制作等。 AI项目与工具 2025年06月12日 16 点赞 0 评论 607 浏览