DeepL Voice DeepL Voice是一款由DeepL推出的即时语音翻译服务,分为DeepL Voice for Meetings和DeepL Voice for Conversations两大模块。前者针对虚拟会议设计,支持实时字幕生成和跨语言协作,兼容超过30种语言并集成Microsoft Teams;后者专注于移动设备上的面对面语音翻译。凭借其低延迟、高性能和高安全性(ISO 27001认证),DeepL AI项目与工具 2025年06月12日 14 点赞 0 评论 897 浏览
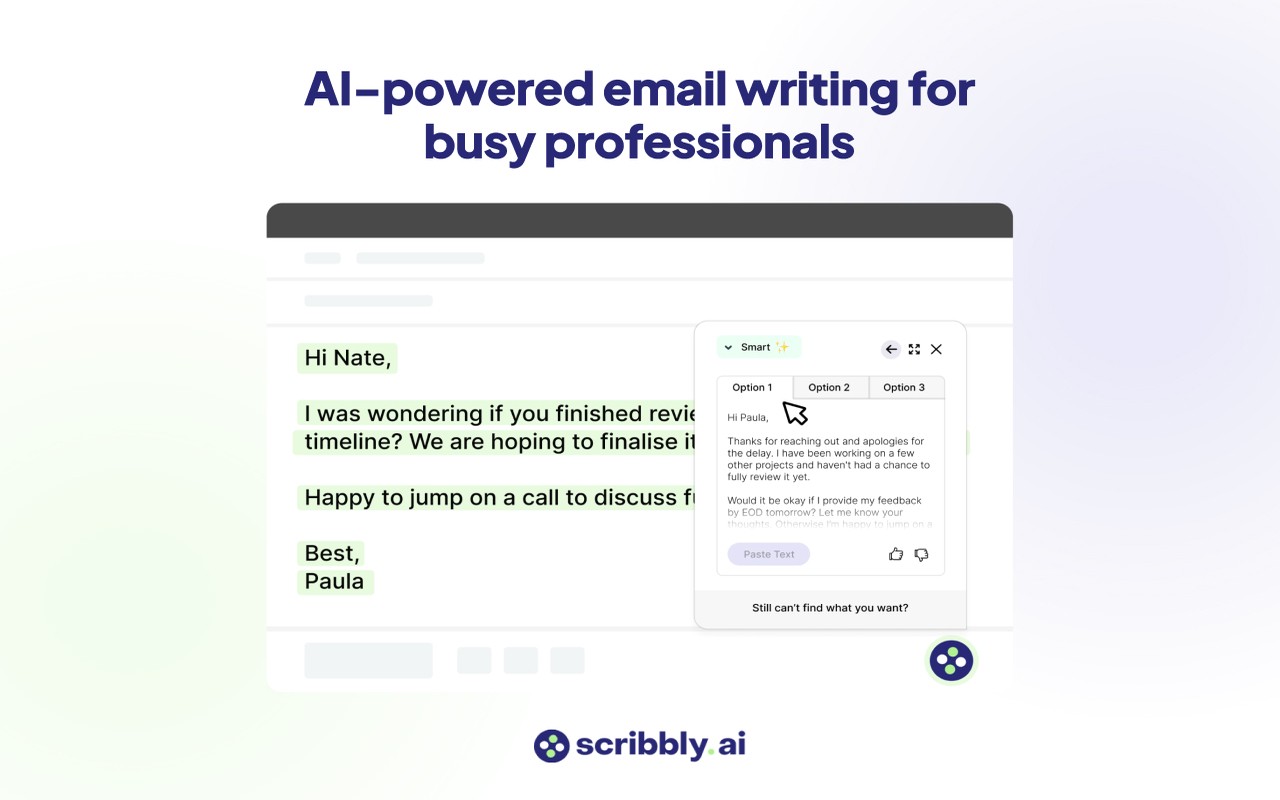
Scribbly AI 一款免费的人工智能电子邮件助手,适用于时间紧迫的专业人士。使用 Scribbly 创建电子邮件的速度可以提高 10 倍,这要归功于听起来与您一样的特定于上下文的内容推荐。 AI写作对话 2025年06月05日 95 点赞 0 评论 897 浏览
Podwise Podwise 是一款基于人工智能的播客知识管理工具,能够将播客内容转化为结构化的文字、总结和思维导图,帮助用户快速掌握核心信息。它支持全球范围内的播客搜索、多语言处理,并可与多种知识管理工具无缝衔接,适用于学习、研究、商业分析等多个场景。 --- AI项目与工具 2025年06月12日 51 点赞 0 评论 897 浏览
Poetry2Image Poetry2Image是一个由哈尔滨工业大学提出的迭代校正框架,专门用于中文古诗词的图像生成。该工具通过自动化反馈和校正机制,提升了诗歌与图像的一致性,解决了文本到图像生成模型在处理中文古典诗歌时常见的关键元素丢失或语义混淆问题。Poetry2Image具备搜索翻译、生成初始图像、提取关键元素、图像修正及迭代优化等功能,与多种图像生成模型结合使用时,其元素完整性和语义一致性表现优异,适用于古诗词 AI项目与工具 2025年06月12日 55 点赞 0 评论 897 浏览
AI Chat AI Chat-avatar 是一款基于AI的数字人交互工具,支持多语言实时翻译与自然对话,适用于销售、客服、培训等多种场景。它能动态展示多媒体内容,提升信息理解度,并提供数据分析报告以优化沟通策略。用户可通过低代码方式快速定制虚拟形象,满足不同业务需求。 AI项目与工具 2025年06月12日 40 点赞 0 评论 898 浏览
OThink OThink-MR1是由OPPO研究院与香港科技大学(广州)联合研发的多模态语言模型优化框架,基于动态KL散度策略(GRPO-D)和奖励模型,提升模型在视觉计数、几何推理等任务中的泛化与推理能力。其具备跨任务迁移能力和动态平衡探索与利用机制,适用于智能视觉问答、图像描述生成、内容审核等多个领域,具有广阔的应用前景。 AI项目与工具 2025年06月12日 21 点赞 0 评论 898 浏览
LatentSync LatentSync是由字节跳动与北京交通大学联合研发的端到端唇形同步框架,基于音频条件的潜在扩散模型,无需中间3D或2D表示,可生成高分辨率、动态逼真的唇同步视频。其核心技术包括Temporal Representation Alignment (TREPA)方法,提升视频时间一致性,并结合SyncNet监督机制确保唇部动作准确。适用于影视制作、教育、广告、远程会议及游戏开发等多个领域。 AI项目与工具 2025年06月12日 95 点赞 0 评论 898 浏览
ARTROOM ARTROOM是一款集成了AI技术的图像生成与编辑平台,支持用户通过图层控制、Loras集成及ControlNets技术生成原创艺术作品或参考图片。平台具备丰富的功能,涵盖个性化定制、灵感获取等,并适用于个人艺术创作、企业营销、教育研究等多个领域,助力用户高效完成高质量视觉内容。 AI项目与工具 2025年06月12日 20 点赞 0 评论 898 浏览
UI UI-TARS是由字节跳动开发的图形用户界面代理模型,支持通过自然语言实现桌面、移动端和网页的自动化交互。具备多模态感知、跨平台操作、视觉识别、任务规划与记忆管理等功能,适用于自动化任务执行和复杂交互场景。支持云端与本地部署,提供丰富的开发接口,便于集成与扩展。 AI项目与工具 2025年06月12日 33 点赞 0 评论 898 浏览