FACTS Grounding FACTS Grounding是一款由谷歌DeepMind研发的基准测试工具,专门用于评估大型语言模型在生成事实准确文本方面的能力。它通过设置包含多个领域的复杂任务,要求模型基于长文档生成响应,并采用两阶段评估流程验证事实准确性及避免“幻觉”。FACTS Grounding不仅支持信息检索与问答,还能应用于内容摘要生成、文档改写以及客户服务等领域,为模型提供全面而可靠的性能评估。 AI项目与工具 2025年06月12日 38 点赞 0 评论 643 浏览
Fox Fox-1是一系列由TensorOpera开发的小型语言模型,基于大规模预训练和微调数据,具备强大的文本生成、指令遵循、多轮对话和长上下文处理能力。该模型在多个基准测试中表现出色,适用于聊天机器人、内容创作、语言翻译、教育辅助和信息检索等多种应用场景。 AI项目与工具 2025年06月12日 60 点赞 0 评论 643 浏览
GEN3C GEN3C是由NVIDIA、多伦多大学和向量研究所联合开发的生成式视频模型,基于点云构建3D缓存,结合精确的相机控制和时空一致性技术,实现高质量视频生成。支持从单视角到多视角的视频创作,具备3D编辑能力,适用于动态场景和长视频生成。在新型视图合成、驾驶模拟、影视制作等领域有广泛应用前景。 AI项目与工具 2025年06月12日 23 点赞 0 评论 644 浏览
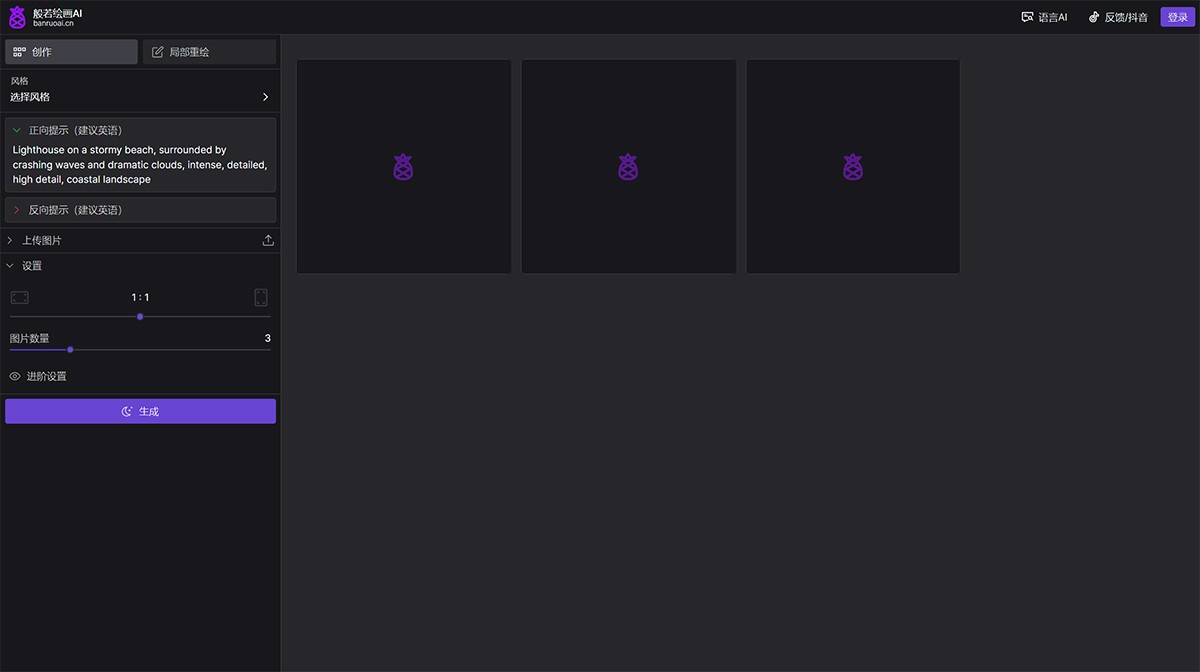
般若AI 提高你的工作效率,提供生活上的便利。般若AI可以帮助人们回答问题,解决诸如文章写作、语言翻译、客服对话、还有强大的AI绘画等多种场景下的需求。 AI写作对话 2025年06月05日 75 点赞 0 评论 644 浏览
PSHuman PSHuman是一款基于跨尺度多视图扩散模型的单图像3D人像重建工具,仅需一张照片即可生成高保真度的3D人体模型,支持全身姿态和面部细节的精确重建。其核心技术包括多视角生成、SMPL-X人体模型融合及显式雕刻技术,确保模型在几何和纹理上的真实感。该工具适用于影视、游戏、VR/AR、时尚设计等多个领域,具备高效、精准和易用的特点。 AI项目与工具 2025年06月12日 49 点赞 0 评论 644 浏览
Askchat.ai 一个基于chatGPT,提供永久角色扮演和prompt工具的人工智能网站,Askchat.ai使用GPT-3.5和GPT-4.0算法进行训练。能够理解和解释人类自然语言,并用合适的方式进行回答。 AI写作对话 2025年06月05日 64 点赞 0 评论 644 浏览
TigerBot TigerBot是一个功能丰富、持续进化的大型语言模型,它通过不断的技术创新和社区贡献,为用户提供了一个强大的多语言多任务处理能力。 Ai平台模型 2026年06月24日 0 点赞 0 评论 644 浏览
IMYAI智能助手 原名ILoveChatGPT,为用户提供丰富的AI服务,使用IMYAI,无需额外工具,即可让您畅享ChatGPT以及Midjourney等AI服务。 Ai平台模型 2025年06月05日 12 点赞 0 评论 645 浏览
Deepfakes Web 一个使用人工智能技术通过交换脸部来轻松生成视频的在线应用程序。该应用程序在云端运行,确保用户数据的隐私。 Ai图片处理 2025年06月05日 23 点赞 0 评论 645 浏览
FancyVideo FancyVideo是一款由360公司与中山大学合作开发的AI文生视频模型,采用创新的跨帧文本引导模块(CTGM)。它能够根据文本描述生成连贯且动态丰富的视频内容,支持高分辨率视频输出,并保持时间上的连贯性。作为开源项目,FancyVideo提供了详尽的文档和代码库,便于研究者和开发者深入研究和应用。主要功能包括文本到视频生成、跨帧文本引导、时间信息注入及时间亲和度细化等。 AI项目与工具 2025年06月12日 28 点赞 0 评论 646 浏览