OptoChat AI OptoChat AI是国内首款面向光子领域的AI大模型,整合超30万条光子芯片相关数据资源,具备强大的数据分析与智能算法能力。可实现光子芯片设计优化、工艺验证、文献检索等功能,显著提升研发效率,缩短设计周期。适用于科研、制造、教育及市场分析等多个场景,推动光子产业智能化发展。 AI项目与工具 2025年06月11日 33 点赞 0 评论 893 浏览
AndroidGen AndroidGen 是一个基于大语言模型(LLM)的智能代理框架,专注于提升 Agent 在数据稀缺环境下的任务执行能力。它通过无监督方式收集用户操作轨迹并进行训练,结合 ExpSearch、ReflectPlan、AutoCheck 和 StepCritic 四个核心模块,增强任务规划、执行和评估能力。该框架在 AndroidWorld 和 AitW 基准测试中表现出色,适用于自动化任务处理、 AI项目与工具 2025年06月12日 31 点赞 0 评论 894 浏览
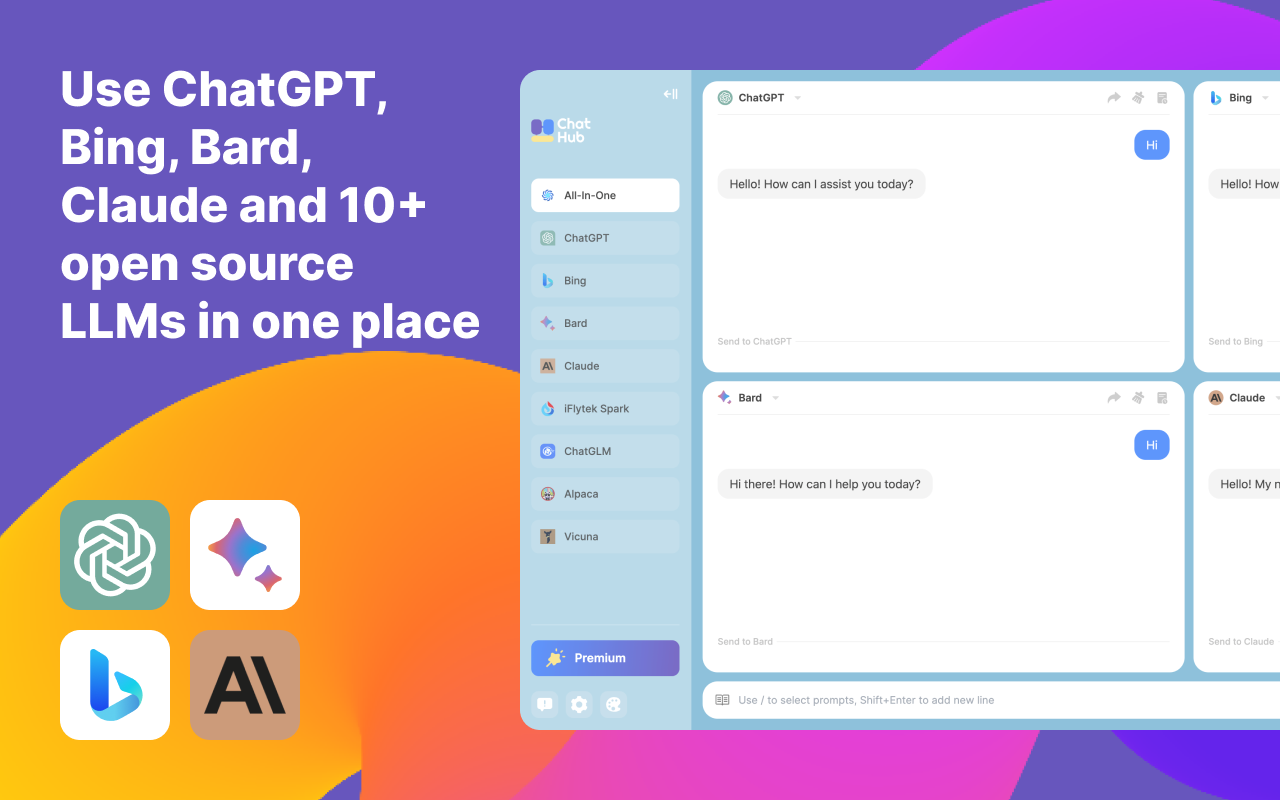
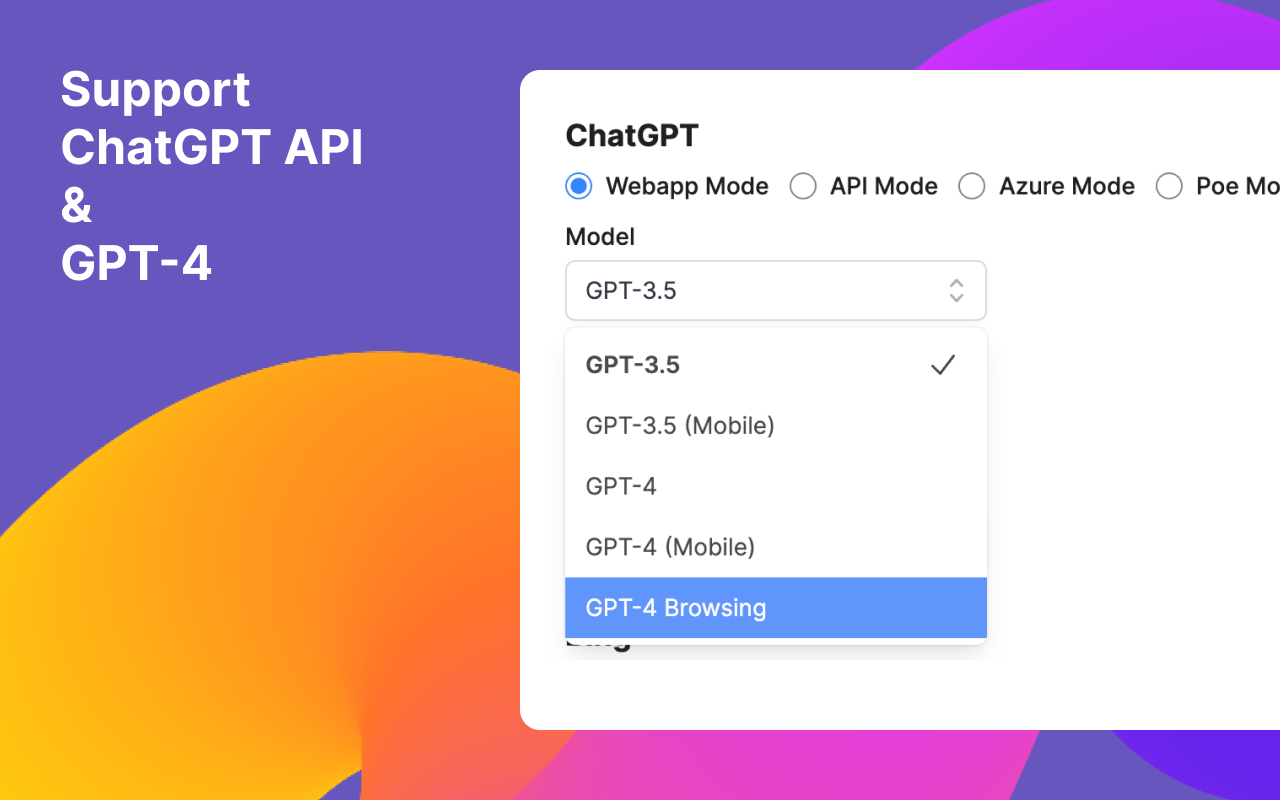
ChatHub 一个创新的浏览器扩展插件和应用,ChatHub设计的目的是为了让用户能够在一个统一的界面中与多个聊天机器人进行交互。 AI写作对话 2025年06月05日 98 点赞 0 评论 894 浏览
Llama 4 Llama 4 是 Meta 推出的多模态 AI 模型系列,采用混合专家(MoE)架构,提升计算效率。包含 Scout 和 Maverick 两个版本,分别适用于不同场景。Scout 支持 1000 万 token 上下文,Maverick 在图像理解和创意写作方面表现优异。Llama 4 支持 200 种语言,具备强大的语言生成与多模态处理能力,适用于对话系统、文本生成、代码辅助、图像分析等多个 AI项目与工具 2025年06月12日 46 点赞 0 评论 896 浏览
联通元景 联通元景(UniT2IXL)是一款基于国产昇腾AI平台开发的中文原生文生图模型,具备卓越的中文语义理解和高质量图像生成能力。它通过复合语言编码模块优化中文长文本处理,并利用大量中文图文数据进行预训练,确保信息完整性和生成质量。该模型支持国产化算力环境,适配多种应用场景,包括文物数字化、个性化服装定制、智能家居设计、广告创意生成及在线教育等,为企业提供高效解决方案。 AI项目与工具 2025年06月12日 54 点赞 0 评论 897 浏览
Sketch2Sound Sketch2Sound是一种由Adobe研究院与西北大学联合开发的AI音频生成技术,通过提取响度、亮度和音高概率等控制信号,结合文本提示生成高质量音效。其轻量化设计使得模型易于适配多种文本到音频框架,同时赋予声音设计师更强的表达力与可控性,广泛适用于电影、游戏、音乐制作及教育等多个领域。 AI项目与工具 2025年06月12日 35 点赞 0 评论 898 浏览
OThink OThink-MR1是由OPPO研究院与香港科技大学(广州)联合研发的多模态语言模型优化框架,基于动态KL散度策略(GRPO-D)和奖励模型,提升模型在视觉计数、几何推理等任务中的泛化与推理能力。其具备跨任务迁移能力和动态平衡探索与利用机制,适用于智能视觉问答、图像描述生成、内容审核等多个领域,具有广阔的应用前景。 AI项目与工具 2025年06月12日 21 点赞 0 评论 898 浏览
LatentSync LatentSync是由字节跳动与北京交通大学联合研发的端到端唇形同步框架,基于音频条件的潜在扩散模型,无需中间3D或2D表示,可生成高分辨率、动态逼真的唇同步视频。其核心技术包括Temporal Representation Alignment (TREPA)方法,提升视频时间一致性,并结合SyncNet监督机制确保唇部动作准确。适用于影视制作、教育、广告、远程会议及游戏开发等多个领域。 AI项目与工具 2025年06月12日 95 点赞 0 评论 898 浏览
UI UI-TARS是由字节跳动开发的图形用户界面代理模型,支持通过自然语言实现桌面、移动端和网页的自动化交互。具备多模态感知、跨平台操作、视觉识别、任务规划与记忆管理等功能,适用于自动化任务执行和复杂交互场景。支持云端与本地部署,提供丰富的开发接口,便于集成与扩展。 AI项目与工具 2025年06月12日 33 点赞 0 评论 898 浏览