FineShare Singify Singify 作为一个 AI 驱动的歌曲翻唱生成器,为用户提供了一个创新的方式来重新演绎和享受音乐。 创作工具 2026年06月23日 0 点赞 0 评论 499 浏览
LM Studio LM Studio是一个开源的本地大语言模型(LLM)应用平台,提供图形用户界面(GUI)和命令行界面(CLI),便于用户使用大型语言模型。LM Studio支持从Hugging Face等平台下载兼容的模型文件,并提供了一种“Playground”模式,用户可以通过该模式同时运行多个AI模型,以增强性能和输出。此外,LM Studio还具备模型发现功能,能够在应用首页展示新的和值得关注的LLMs AI项目与工具 2025年06月12日 42 点赞 0 评论 499 浏览
FlowiseAI FlowiseAI 是一款开源的低代码 AI 工具,允许用户通过可视化拖拽方式快速构建大型语言模型应用。支持多模型集成、对话记忆、API 接口等功能,适用于聊天机器人、工作流自动化和文档问答等多种场景。提供本地、Docker 和云平台部署方式,适合开发者和企业用户进行灵活应用开发。 AI项目与工具 2025年06月12日 18 点赞 0 评论 499 浏览
Pippo Pippo是由Meta Reality Labs研发的图像到视频生成模型,可基于单张照片生成多视角高清人像视频。采用多视角扩散变换器架构,结合ControlMLP模块与注意力偏差技术,实现更丰富的视角生成和更高的3D一致性。支持高分辨率输出及细节自动补全,适用于虚拟现实、影视制作、游戏开发等多个领域。技术方案涵盖多阶段训练流程,确保生成质量与稳定性。 AI项目与工具 2025年06月12日 38 点赞 0 评论 500 浏览
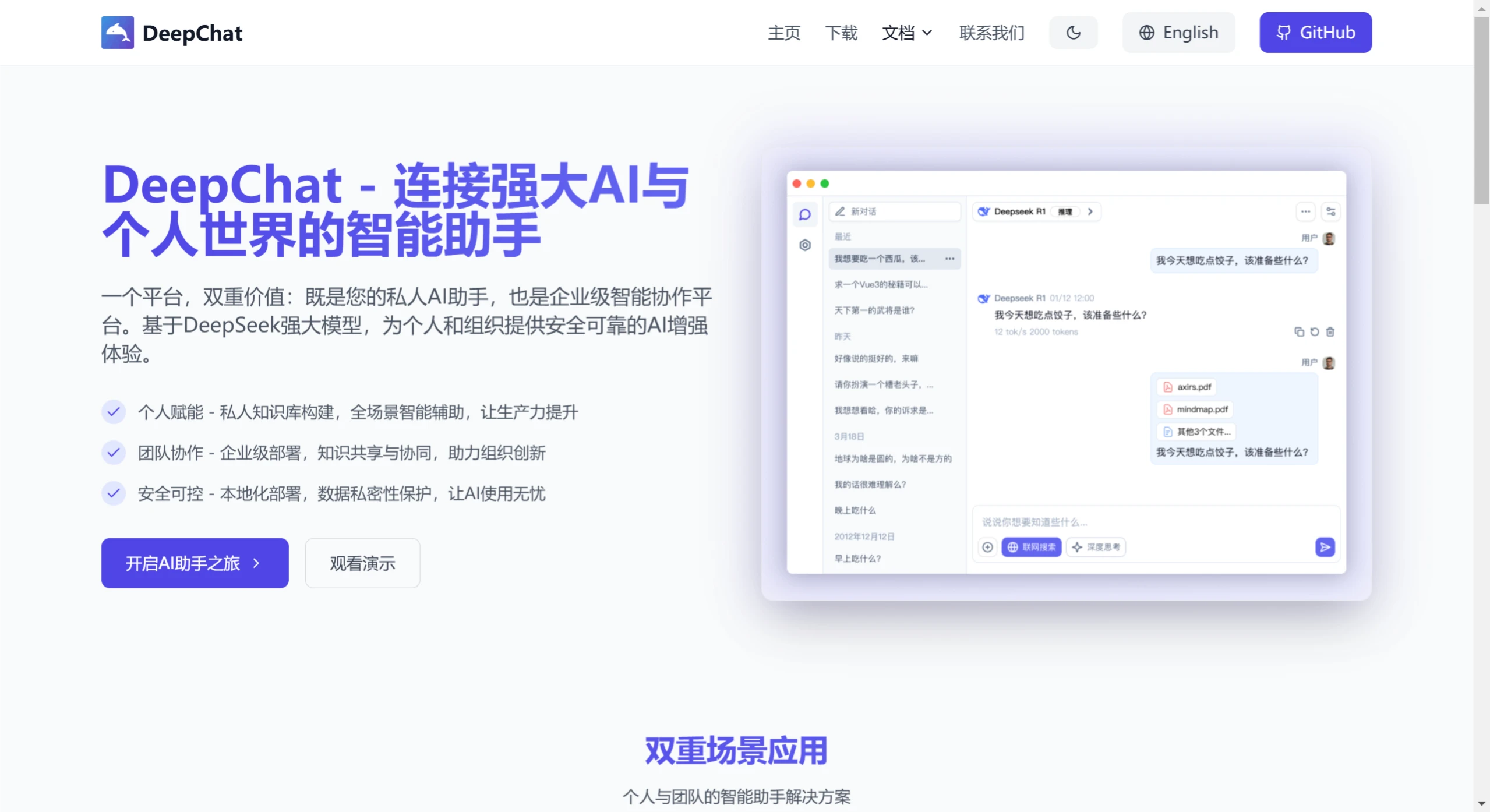
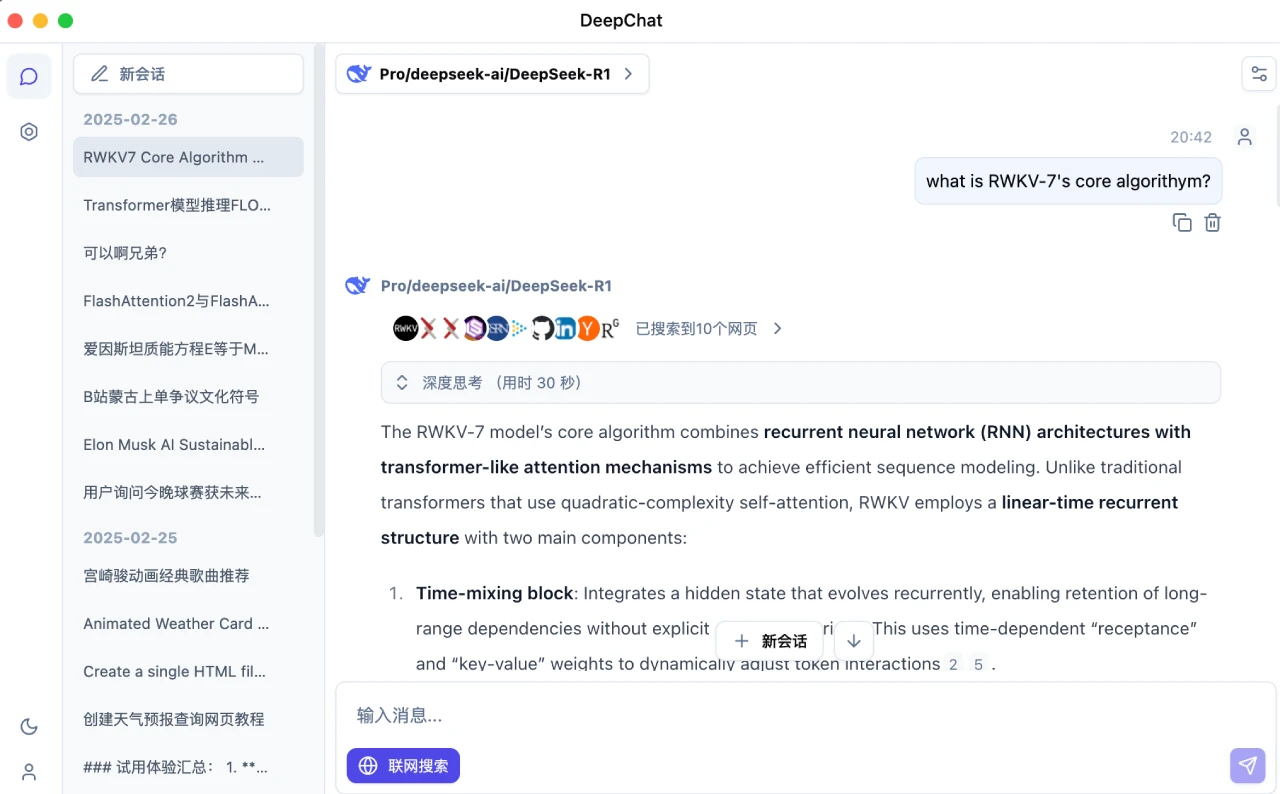
DeepChat 一款开源的AI聊天客户端,内置强大的 DeepSeek 大模型,支持多轮对话、联网搜索、文件上传、知识库等多种功能。 Ai平台模型 2025年06月05日 55 点赞 0 评论 500 浏览
DeerFlow DeerFlow 是字节跳动推出的开源研究框架,结合语言模型与多种工具,支持高效完成复杂研究任务。具备多Agent架构,支持自然语言交互与智能协作,适用于研究报告、播客、演示文稿等内容生成。支持多种语言模型和外部工具集成,提供灵活配置与扩展能力,广泛应用于学术、市场、教育及个人知识管理等领域。 AI项目与工具 2025年06月11日 23 点赞 0 评论 500 浏览
oli oli 是一款开源的智能代码助手,结合 Rust 后端与 React/Ink 前端,提供高效的代码辅助、文件操作、命令执行等功能。支持多模型集成,包括云 API 和本地 LLM,适用于代码理解、优化、开发调试及项目管理等场景,提升开发效率和用户体验。 AI项目与工具 2025年06月11日 35 点赞 0 评论 500 浏览
Proactive Agent Proactive Agent是一款由清华大学主导开发的主动式AI代理系统,它通过观察环境和用户行为来预测需求并自主发起任务,无需依赖明确指令即可完成操作。主要功能包括环境感知、上下文理解、任务执行及用户互动优化等。此外,该系统采用先进的环境模拟技术和奖励机制进行训练与评估,广泛应用于个人助理、文件管理、生活服务等多个领域。 AI项目与工具 2025年06月12日 86 点赞 0 评论 501 浏览
Gemini 2.0 Gemini 2.0 是谷歌推出的原生多模态AI模型,具备快速处理文本、音频和图像的能力,支持多语言输出和实时音视频流输入。通过Agent技术和工具调用,Gemini 2.0 能够自主理解任务并提供解决方案,已在编程、数据分析、游戏等领域展示应用潜力。目前提供免费试用,计划逐步开放更多功能。 AI项目与工具 2025年06月12日 63 点赞 0 评论 501 浏览
Llama Nemotron Llama Nemotron是NVIDIA推出的推理模型系列,具备强大的复杂推理、多任务处理和高效对话能力,适用于企业级AI代理应用。模型基于Llama架构优化,采用神经架构搜索与知识蒸馏技术,提升计算效率。包含Nano、Super和Ultra三种版本,分别面向边缘设备、数据中心和高性能计算场景。广泛应用于科研、客服、医疗、物流和金融等领域。 AI项目与工具 2025年06月12日 72 点赞 0 评论 502 浏览