扩散模型



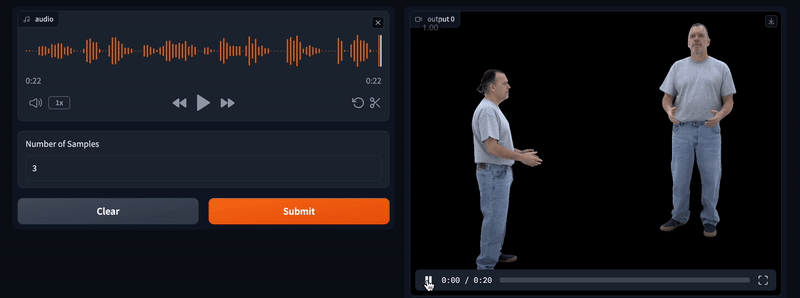





MVGenMaster
MVGenMaster是一款基于多视图扩散模型的工具,利用增强的3D先验技术实现新视角合成任务。它可以从单一图像生成多达100个新视图,具有高度的灵活性和泛化能力。模型结合了度量深度、相机姿态扭曲以及全注意力机制等技术,支持高效的前向传播过程,同时兼容大规模数据集。MVGenMaster在视频游戏、电影特效、虚拟现实、3D建模及建筑可视化等领域具有广泛应用前景。

