Awesome Chinese LLM 整理了开源的中文大语言模型(LLM),主要关注规模较小、可私有化部署且训练成本较低的模型,目前已收录了100多个相关资源。 Ai学习资源 2025年06月05日 44 点赞 0 评论 577 浏览
Awesome MCP Servers Awesome MCP Servers 是一个开源项目,整合了超过 3000 个基于 Model Context Protocol (MCP) 的服务器资源,覆盖浏览器自动化、金融、游戏、安全、科研等多个领域。它支持本地和云部署,提供丰富的开发工具和社区支持,使 AI 模型能够高效调用外部数据和服务,提升应用灵活性与功能性。 AI项目与工具 2025年06月12日 74 点赞 0 评论 579 浏览
Laminar Laminar是一款面向大型语言模型(LLM)的开源可观测性和分析平台,具备自动追踪LLM调用与数据库交互、事件驱动分析及数据标注等功能,同时支持高效的数据存储与可视化展示。其目标是提升LLM应用的透明度和效率,适用于开发调试、性能监控、用户体验优化及业务决策支持等多个场景。 AI项目与工具 2025年06月12日 98 点赞 0 评论 579 浏览
零沫AI工具导航 一个AI垂直类交流社区,一直专注AI领域发展,零沫AI收录了国内外数百个不同类型的AI工具,每日更新和添加最新AI工具。 Ai学习资源 2025年06月05日 13 点赞 0 评论 579 浏览
Zonos Zonos是一款由Zyphra开发的高保真文本到语音(TTS)模型,支持零样本语音克隆和多语言生成,具备精细的情感与语音参数控制能力。其采用Transformer和SSM混合架构,基于大规模语音数据训练,适用于有声读物、虚拟助手、多媒体创作及无障碍技术等多个领域。模型开源且支持实时语音生成,具有广泛的应用潜力。 AI项目与工具 2025年06月12日 69 点赞 0 评论 580 浏览
乾元BigBangTransformer BBT-2-12B-Text基于中文700亿tokens进行预训练,经过指令微调的BBT-2基础模型可以回答百科类和日常生活的问题。BBT-2.5-13B-Text基于中文+英文 2000亿tokens进行预训练。 Ai平台模型 2026年06月23日 0 点赞 0 评论 580 浏览
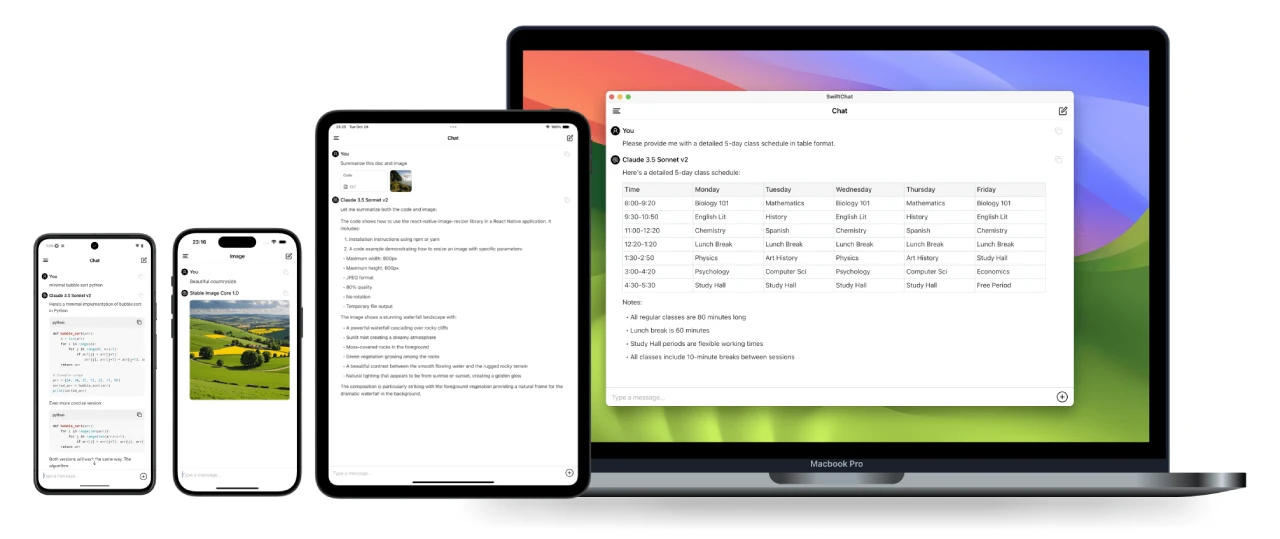
SwiftChat 一款基于React Native开发的快速、安全、跨平台聊天应用,支持实时流式聊天功能和Markdown语法,还可以生成AI图像,兼容DeepSeek、Amazon Bedrock、Ollama和OpenAI等模型。 Ai开源项目 2025年06月05日 44 点赞 0 评论 582 浏览
NewsNow 一款开源的实时热门新闻聚合平台,能让你快速了解国内外的新闻、科技和财经动态。它把微博、知乎、Hacker News 等多个平台的热门榜单都整合在一起,方便你一站式获取信息。 实时热榜 2025年06月05日 69 点赞 0 评论 582 浏览
Marker Marker 是一款开源的高精度文档转换工具,支持 PDF、Word 等多种格式向 Markdown、JSON 和 HTML 的转换。它利用深度学习技术自动去除干扰元素,支持多语言处理,具备表格、代码块、公式识别及图像提取等功能,适用于学术研究、技术文档、教育资料等多种场景。同时支持硬件加速和批量处理,提升转换效率与用户体验。 AI项目与工具 2025年06月12日 26 点赞 0 评论 584 浏览