Product Avatar Product Avatar 是一款由 TopView 推出的 AI 工具,能够将产品图片转化为由虚拟人物手持展示的视频内容。用户只需上传图片并选择模板,即可生成高质量视频,无需真人模特。支持多语言与唇形同步,适用于电商、社交媒体及广告营销等场景,帮助品牌提升产品展示效果与全球市场沟通能力。 AI项目与工具 2025年06月12日 94 点赞 0 评论 734 浏览
FullStack Bench FullStack Bench是一款由字节跳动与M-A-P社区联合推出的专业代码评估工具,主要针对全栈编程和多语言编程能力进行评估。它包含11种真实编程场景、3374个问题以及16种编程语言,具备全面评估、多语言支持、实际场景模拟、代码质量控制等特点,适用于代码智能评估、教育与培训、研究开发、软件测试及多语言编程能力评估等多个场景。 AI项目与工具 2025年06月12日 40 点赞 0 评论 733 浏览
GPTGO AI 一款结合了 Google 搜索技术和GPT智能响应功能的强大的AI搜索工具。这个AI搜索引擎提供了一种现代和创新的搜索方法,为用户提供智能结果和无缝的搜索体验。 Ai办公效率 2025年06月05日 41 点赞 0 评论 732 浏览
Supermeme.Ai Supermeme.ai是一个表情包生成器,可以生成110多种语言的表情包。可以添加自己的文本,调整字体大小和移动元素,轻松简单的生成各种奇奇怪怪的表情包。 Ai图片处理 2025年06月05日 27 点赞 0 评论 730 浏览
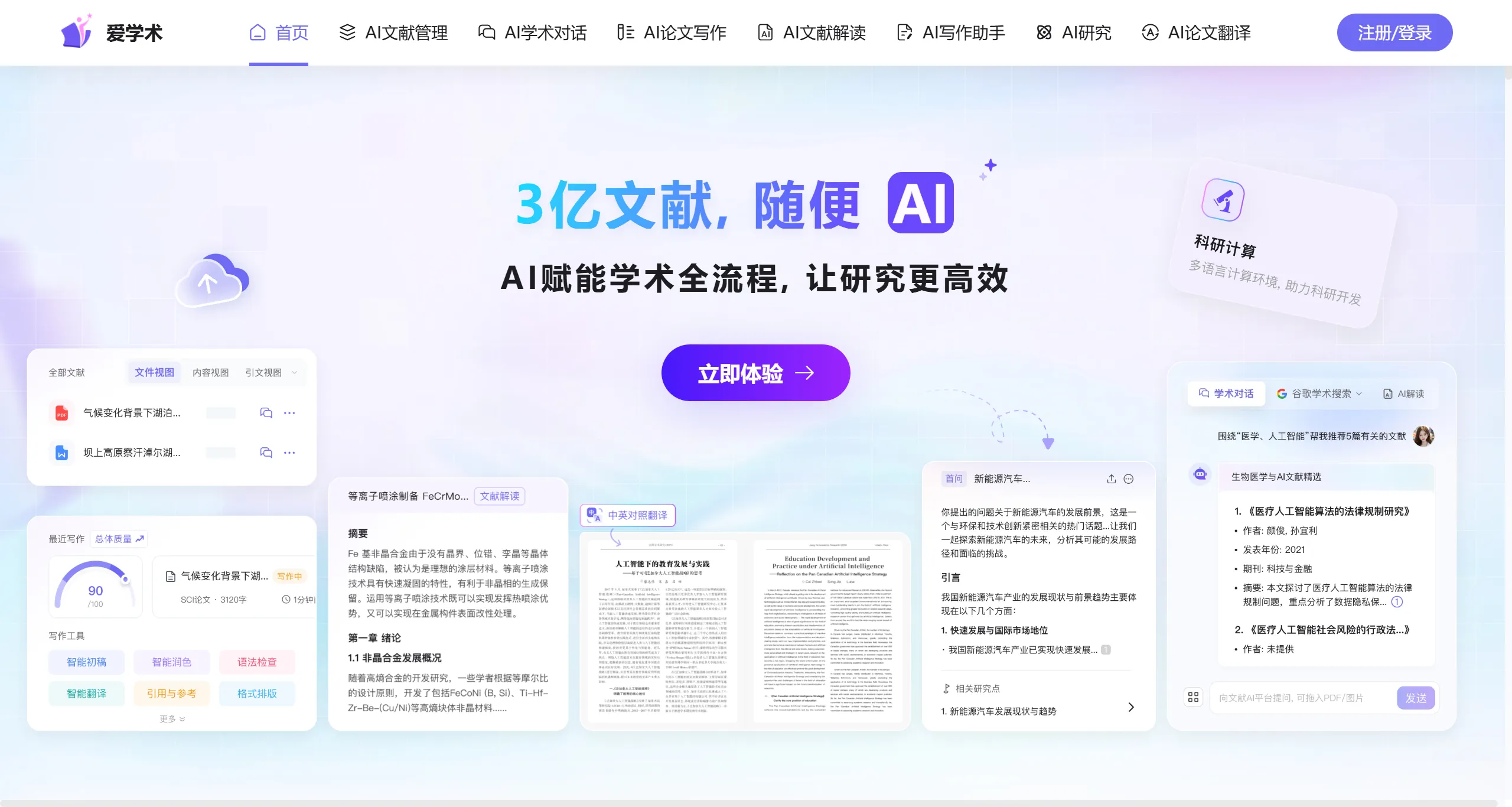
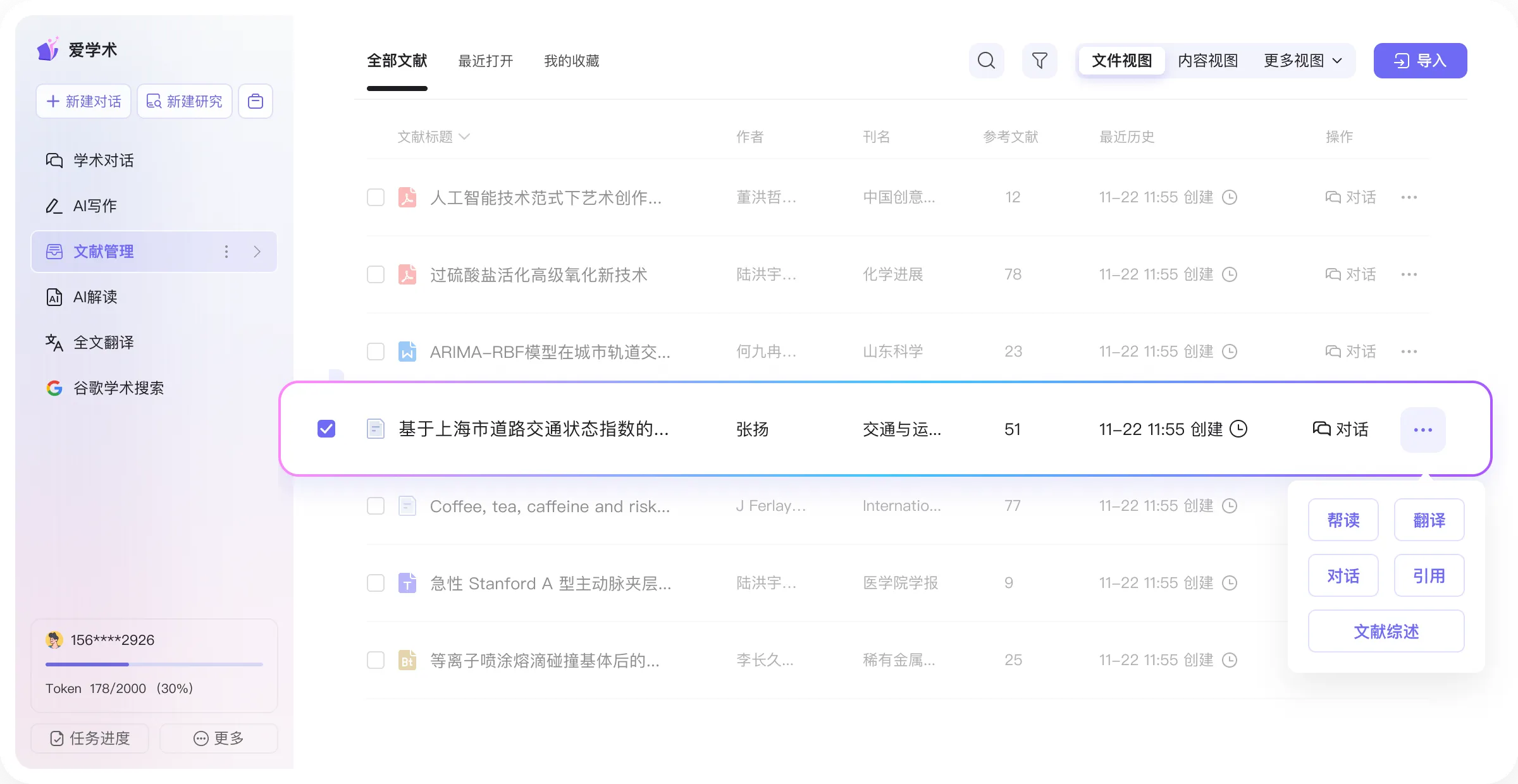
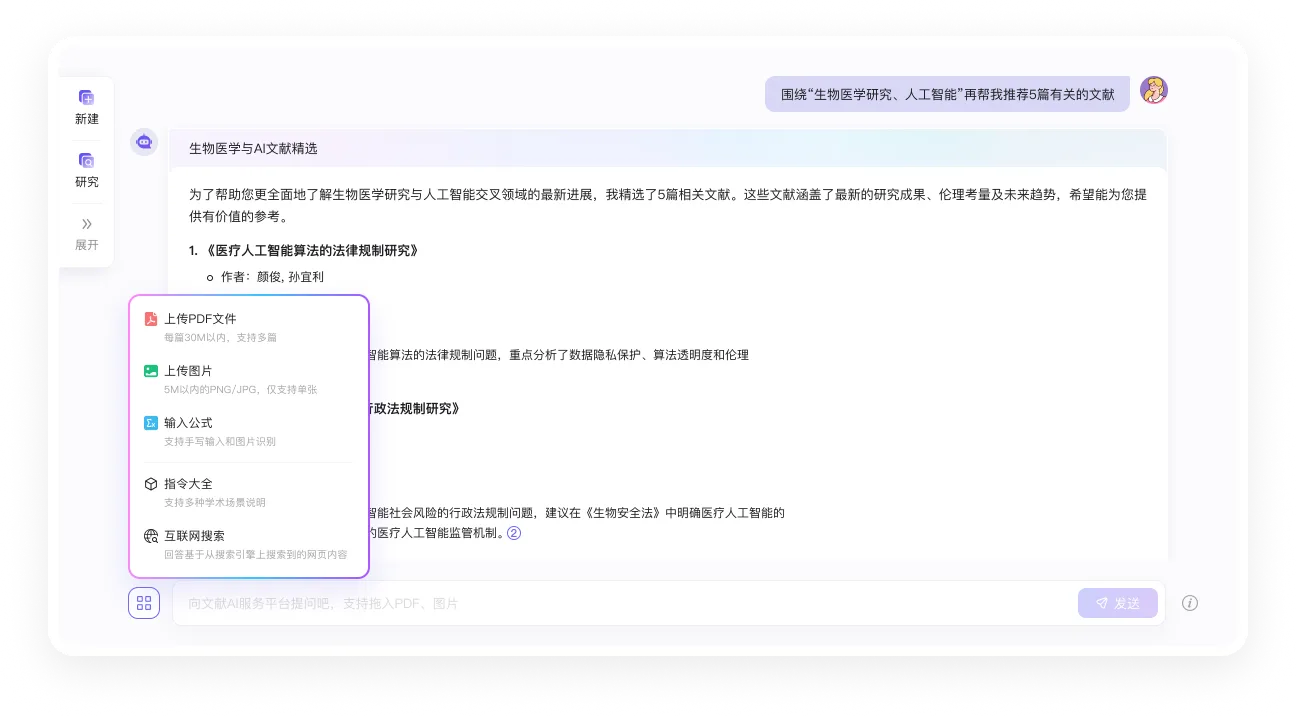
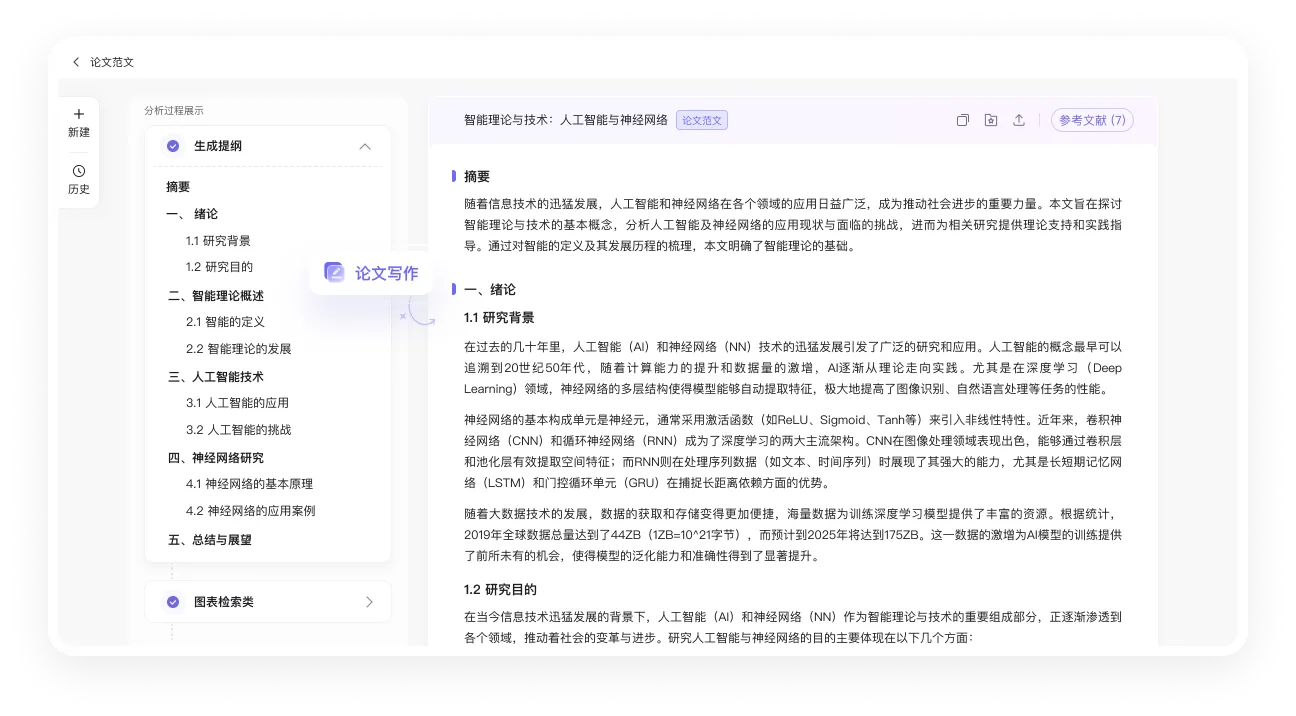
爱学术 一款AI文献阅读器,依托自主研发的AI学术大模型打造的智能文献管理平台,爱学术AI提供AI文献管理、AI学术对话、AI论文写作、AI文献解读、AI写作助手、AI研究、AI论文翻译等功能。 教育学习 2025年06月05日 53 点赞 0 评论 729 浏览
Shulex Copilot 一款为亚马逊和Shopify卖家量身打造的强大AI助手。它利用ChatGPT/GPT4技术帮助卖家分析亚马逊评论,优化亚马逊列表,并提升客户服务。 电商运营 2025年06月05日 27 点赞 0 评论 728 浏览
Replit Agent Replit Agent是一款由AI初创公司Replit开发的编程工具,支持用户通过自然语言描述来构建软件项目。该工具具备自动化编程、快速原型开发、简化部署流程等功能,可在手机或电脑上快速创建应用程序。Replit Agent不仅提高了开发效率,还降低了编程门槛,适用于多种应用场景,包括教育、原型开发和移动应用开发等。 AI项目与工具 2024年09月12日 74 点赞 0 评论 728 浏览
VERBALATE VERBALATE是一款基于AI的视频翻译与配音工具,支持多语言翻译及口型同步,适用于教育、娱乐、企业培训等场景。其主要功能包括视频翻译、声音克隆、口型同步、多语言支持及长视频处理,界面友好且操作简便,为企业和个人用户提供高效的多语言内容解决方案。 AI项目与工具 2025年06月12日 97 点赞 0 评论 728 浏览
Byrdhouse Byrdhouse 是一个创新的视频会议平台,它通过集成人工智能技术,为用户提供实时翻译服务,从而消除语言障碍,让不同语言的使用者能够无缝沟通和协作。 创作工具 2026年06月24日 0 点赞 0 评论 727 浏览