Diffuse to Choose 一种基于扩散的图像修复模型,主要用于虚拟试穿场景。它能够在修复图像时保留参考物品的细节,适用于在线购物等虚拟试穿场景中的图像修复任务。 Ai开源项目 2025年06月05日 74 点赞 0 评论 721 浏览
ChatDOC ChatDOC是一款基于ChatGPT技术的智能文件阅读助手,它可以快速解析、定位和总结上传的PDF文件内容。用户可以通过与AI助手的对话式学习,深入挖掘文本结构和内容。 Ai办公效率 2026年06月24日 0 点赞 0 评论 721 浏览
MakeLogoAI Make Logo AI是一个人工智能驱动的Logo生成器,允许用户在不到24小时内为他们的企业创建独特的高清Logo。 Ai绘画生成 2026年06月24日 0 点赞 0 评论 722 浏览
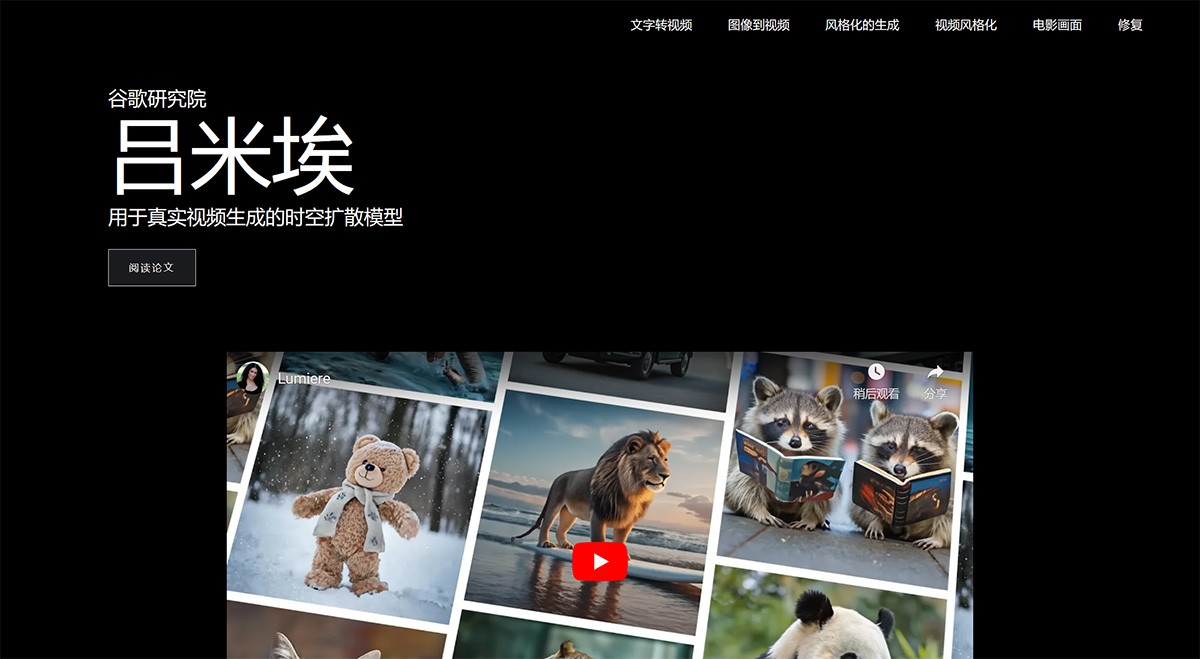
Lumiere 谷歌研究院开发的基于空间时间的文本到视频扩散模型。采用了创新的空间时间U-Net架构,能够一次性生成整个视频的时间长度,确保了生成视频的连贯性和逼真度。 Ai开源项目 2025年06月05日 74 点赞 0 评论 722 浏览
Remaker Remaker是一个在线AI工具,专注于创意内容的生成。它利用生成式AI技术,为用户提供了多种功能,包括AI换脸、批量换脸、多人换脸、视频换脸等,满足不同场景下的内容创作需求。 Ai视频生成 2026年06月24日 0 点赞 0 评论 722 浏览
CogVideo 目前最大的通用领域文本生成视频预训练模型,含94亿参数。CogVideo将预训练文本到图像生成模型(CogView2)有效地利用到文本到视频生成模型,并使用了多帧率分层训练策略。 Ai平台模型 2025年06月05日 16 点赞 0 评论 722 浏览